Quick description
You want to prove some statement 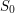 about some object
about some object 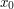 (which could be a number, a point, a function, a set, etc.). To do so, pick a small
(which could be a number, a point, a function, a set, etc.). To do so, pick a small 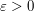 , and first prove a weaker statement
, and first prove a weaker statement 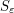 (which allows for “losses” which go to zero as
(which allows for “losses” which go to zero as 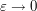 ) about some perturbed object
) about some perturbed object 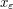 . Then, take limits . Provided that the dependency and continuity of the weaker conclusion on
. Then, take limits . Provided that the dependency and continuity of the weaker conclusion on  are sufficiently controlled, and is converging to in an appropriately strong sense, you will recover the original statement.
are sufficiently controlled, and is converging to in an appropriately strong sense, you will recover the original statement.
One can of course play a similar game when proving a statement 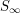 about some object
about some object 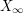 , by first proving a weaker statement
, by first proving a weaker statement 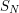 on some approximation
on some approximation 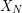 to for some large parameter N, and then send
to for some large parameter N, and then send 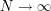 at the end.
at the end.
General discussion
The first, simplest instance of this trick would be to prove that an object satisfies a property 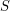 , which we know that conmutes with a limit in some sense, by finding a sequence of objects
, which we know that conmutes with a limit in some sense, by finding a sequence of objects 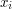 such that is invariant on it and such that it converges (in the same limit sense) to .♦ The power of the method goes in the difficulty of proving the satisfaction of : should be easy to prove for every by some standard techniques, but difficult for with the same techniques. Note that this instance is somewhat the "reciprocal" of a limiting process (where we replace a sequence by its limit).
such that is invariant on it and such that it converges (in the same limit sense) to .♦ The power of the method goes in the difficulty of proving the satisfaction of : should be easy to prove for every by some standard techniques, but difficult for with the same techniques. Note that this instance is somewhat the "reciprocal" of a limiting process (where we replace a sequence by its limit).
But of course, we don't need to be invariant in the sequence: we just need to have a perturbed property 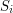 for every such that converges to as converges to . Moreover, we don't need the index set to be countable: we can use a net; for example, we can indize with the reals and use the variable .
for every such that converges to as converges to . Moreover, we don't need the index set to be countable: we can use a net; for example, we can indize with the reals and use the variable .
Here are some typical examples of a target statement , and the approximating statements that would converge to :
|
|
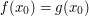 |
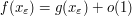 |
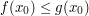 |
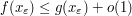 |
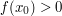 |
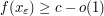 for some for some 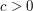 independent of independent of |
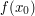 is finite is finite |
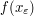 is bounded uniformly in is bounded uniformly in |
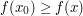 for all for all 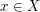 (i.e. maximises f) (i.e. maximises f) |
 for all (i.e. nearly maximises f) for all (i.e. nearly maximises f) |
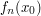 converges as converges as 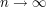 |
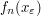 fluctuates by at most o(1) for sufficiently large n fluctuates by at most o(1) for sufficiently large n |
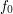 is a measurable function is a measurable function |
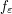 is a measurable function converging pointwise to is a measurable function converging pointwise to |
| is a continuous function |
is an equicontinuous family of functions converging pointwise to OR is continuous and converges (locally) uniformly to |
The event 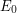 holds almost surely holds almost surely |
The event 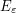 holds with probability 1-o(1) holds with probability 1-o(1) |
The statement 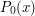 holds for almost every x holds for almost every x |
The statement 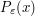 holds for x outside of a set of measure o(1) holds for x outside of a set of measure o(1) |
Of course, to justify the convergence of to , it is necessary that converge to (or converge to , etc.) in a suitably strong sense. (But for the purposes of proving just upper bounds, such as 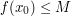 , one can often get by with quite weak forms of convergence, thanks to tools such as Fatou's lemma or the weak closure of the unit ball.) Similarly, we need some continuity (or at least semi-continuity) hypotheses on the functions f, g appearing above.
, one can often get by with quite weak forms of convergence, thanks to tools such as Fatou's lemma or the weak closure of the unit ball.) Similarly, we need some continuity (or at least semi-continuity) hypotheses on the functions f, g appearing above.
It is also necessary in many cases that the control on the approximating object is somehow "uniform in ", although for " -closed" conclusions, such as measurability, this is not required. [It is important to note that it is only the final conclusion on that needs to have this uniformity in ; one is permitted to have some intermediate stages in the derivation of that depend on in a non-uniform manner, so long as these non-uniformities cancel out or otherwise disappear at the end of the argument.]
-closed" conclusions, such as measurability, this is not required. [It is important to note that it is only the final conclusion on that needs to have this uniformity in ; one is permitted to have some intermediate stages in the derivation of that depend on in a non-uniform manner, so long as these non-uniformities cancel out or otherwise disappear at the end of the argument.]
By giving oneself an epsilon of room, one can evade a lot of familiar issues in soft analysis. For instance, by replacing "rough", "infinite-complexity", "continuous", "global", or otherwise "infinitary" objects with "smooth", "finite-complexity", "discrete", "local", or otherwise "finitary" approximants , one can finesse most issues regarding the justification of various formal operations (e.g. exchanging limits, sums, derivatives, and integrals). [It is important to be aware, though, that any quantitative measure on how smooth, discrete, finite, etc. should be expected to degrade in the limit , and so one should take extreme caution in using such quantitative measures to derive estimates that are uniform in .] Similarly, issues such as whether the supremum 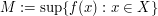 of a function on a set is actually attained by some maximiser become moot if one is willing to settle instead for an almost-maximiser , e.g. one which comes within an epsilon of that supremum M (or which is larger than
of a function on a set is actually attained by some maximiser become moot if one is willing to settle instead for an almost-maximiser , e.g. one which comes within an epsilon of that supremum M (or which is larger than 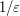 , if M turns out to be infinite). Last, but not least, one can use the epsilon room to avoid degenerate solutions, for instance by perturbing a non-negative function to be strictly positive, perturbing a non-strictly monotone function to be strictly monotone, and so forth.
, if M turns out to be infinite). Last, but not least, one can use the epsilon room to avoid degenerate solutions, for instance by perturbing a non-negative function to be strictly positive, perturbing a non-strictly monotone function to be strictly monotone, and so forth.
In applying the epsilon regularization trick, one often needs to approximate rough functions by smooth ones. One useful way of doing so is to use the trick "To make a function nicer without changing it much, convolve it with an approximate delta function".
To summarise: one can view the epsilon regularisation argument as a "loan" in which one borrows an epsilon here and there in order to be able to ignore soft analysis difficulties, and can temporarily be able to utilise estimates which are non-uniform in epsilon, but at the end of the day one needs to "pay back" the loan by establishing a final "hard analysis" estimate which is uniform in epsilon (or whose error terms decay to zero as epsilon goes to zero).
A variant: It may seem that the epsilon regularisation trick is useless if one is already in "hard analysis" situations when all objects are already "finitary", and all formal computations easily justified. However, there is an important variant of this trick which applies in this case: namely, instead of sending the epsilon parameter to zero, choose epsilon to be a sufficiently small (but not infinitesimally small) quantity, depending on other parameters in the problem, so that one can eventually neglect various error terms and to obtain a useful bound at the end of the day. (For instance, any result proven using the Szemerédi regularity lemma is likely to be of this type.) Since one is not sending epsilon to zero, not every term in the final bound needs to be uniform in epsilon, though for quantitative applications one still would like the dependencies on such parameters to be as favourable as possible.
Prerequisites
Graduate real analysis. (Actually, this isn't so much a prerequisite as it is a corequisite: the limiting argument plays a central role in many fundamental results in real analysis.) Some examples also require some exposure to PDE.
Example 1
The "soft analysis" components of any real analysis textbook will contain a large number of examples of this trick in action. In particular, any argument which exploits Littlewood's three principles of real analysis is likely to utilise this trick.◊
Example 2: The Riemann-Lebesgue lemma
Given any absolutely integrable function 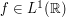 , the Fourier transform
, the Fourier transform 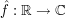 is defined by the formula
is defined by the formula
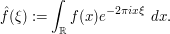
The Riemann-Lebesgue lemma asserts that 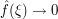 as
as 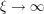 . It is difficult to prove this estimate for f directly, because this function is too "rough": it is absolutely integrable (which is enough to ensure that
. It is difficult to prove this estimate for f directly, because this function is too "rough": it is absolutely integrable (which is enough to ensure that 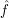 exists and is bounded), but need not be continuous, differentiable, compactly supported, bounded, or otherwise "nice". But suppose we give ourselves an epsilon of room. Then, as the space
exists and is bounded), but need not be continuous, differentiable, compactly supported, bounded, or otherwise "nice". But suppose we give ourselves an epsilon of room. Then, as the space 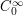 of test functions is dense in
of test functions is dense in 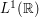 , we can approximate
, we can approximate 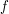 to any desired accuracy in the
to any desired accuracy in the 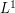 norm by a smooth, compactly supported function
norm by a smooth, compactly supported function 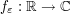 , thus
, thus
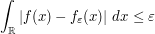
The point is that is much better behaved than f, and it is not difficult to show the analogue of the Riemann-Lebesgue lemma for . Indeed, being smooth and compactly supported, we can now justifiably integrate by parts to obtain
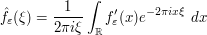
for any non-zero  , and it is now clear (since
, and it is now clear (since  is bounded and compactly supported) that
is bounded and compactly supported) that 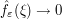 as .
as .
Now we need to take limits as . It will be enough to have 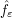 converge uniformly to . But from (1) and the basic estimate
converge uniformly to . But from (1) and the basic estimate
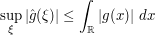
(which is the single "hard analysis" ingredient in the proof of the lemma) applied to 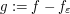 , we see (by the linearity of the Fourier transform) that
, we see (by the linearity of the Fourier transform) that
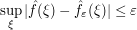
and we obtain the desired uniform convergence.
is continuous; we leave this as an exercise to the reader.Example 3
The limiting argument in the previous example relied on the linearity of the Fourier transform  . But, with more effort, it is also possible to extend this type of argument to nonlinear settings. We will sketch (omitting several technical details, which can be found for instance in this PDE book) a very typical instance. Consider a nonlinear PDE, e.g. the nonlinear wave equation
. But, with more effort, it is also possible to extend this type of argument to nonlinear settings. We will sketch (omitting several technical details, which can be found for instance in this PDE book) a very typical instance. Consider a nonlinear PDE, e.g. the nonlinear wave equation
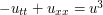
where 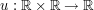 is some scalar field, and the t and x subscripts denote differentiation of the field
is some scalar field, and the t and x subscripts denote differentiation of the field 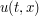 . Formally - if u is sufficiently smooth, and sufficiently decaying at spatial infinity, one can show that the energy
. Formally - if u is sufficiently smooth, and sufficiently decaying at spatial infinity, one can show that the energy
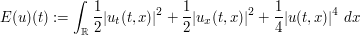
is conserved, thus 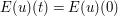 for all t. This can be formally justified by computing the derivative
for all t. This can be formally justified by computing the derivative 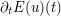 by differentiating under the integral sign, integrating by parts, and then applying the PDE (3); we leave this as an exercise for the reader. (There are also more fancy ways to see why the energy is conserved, using Hamiltonian or Lagrangian mechanics or by the more general theory of stress-energy tensors, but we will not discuss these here.) However, these justifications do require a fair amount of regularity on the solution u; for instance, requiring u to be three-times continuously differentiable in space and time, and compactly supported in space on each bounded time interval, would be sufficient to make the computations rigorous by applying "off the shelf" theorems about differentiation under the integration sign, etc.
by differentiating under the integral sign, integrating by parts, and then applying the PDE (3); we leave this as an exercise for the reader. (There are also more fancy ways to see why the energy is conserved, using Hamiltonian or Lagrangian mechanics or by the more general theory of stress-energy tensors, but we will not discuss these here.) However, these justifications do require a fair amount of regularity on the solution u; for instance, requiring u to be three-times continuously differentiable in space and time, and compactly supported in space on each bounded time interval, would be sufficient to make the computations rigorous by applying "off the shelf" theorems about differentiation under the integration sign, etc.
But suppose one only has a much rougher solution, for instance an energy class solution which has finite energy (4), but for which higher derivatives of u need not exist in the classical sense. (There is a non-trivial issue regarding how to make sense of the PDE (3) when u is only in the energy class, since the terms 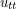 and
and 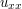 do not then make sense classically, but there are standard ways to deal with this, e.g. using weak derivatives, which we will not discuss further here.) Then it is difficult to justify the energy conservation law directly. However, it is still possible to obtain energy conservation by the limiting argument. Namely, one takes the energy class solution u at some initial time (e.g. t=0) and approximates that initial data (the initial position
do not then make sense classically, but there are standard ways to deal with this, e.g. using weak derivatives, which we will not discuss further here.) Then it is difficult to justify the energy conservation law directly. However, it is still possible to obtain energy conservation by the limiting argument. Namely, one takes the energy class solution u at some initial time (e.g. t=0) and approximates that initial data (the initial position 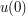 and initial data
and initial data 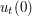 ) by a much smoother (and compactly supported) choice
) by a much smoother (and compactly supported) choice 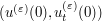 of initial data, which converges back to
of initial data, which converges back to 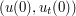 in a suitable "energy topology" related to (4) which we will not define here. It then turns out (from the existence theory of the PDE (3)) that one can extend the smooth initial data to other times t, providing a smooth solution
in a suitable "energy topology" related to (4) which we will not define here. It then turns out (from the existence theory of the PDE (3)) that one can extend the smooth initial data to other times t, providing a smooth solution 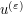 to that data. For this solution, the energy conservation law
to that data. For this solution, the energy conservation law 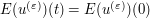 can be justified.
can be justified.
Now we take limits as (keeping t fixed). Since converges in the energy topology to , and the energy functional E is continuous in this topology, 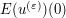 converges to
converges to 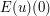 . To conclude the argument, we will also need
. To conclude the argument, we will also need 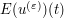 to converge to
to converge to 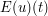 , which will be possible if
, which will be possible if 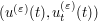 converges in the energy topology to
converges in the energy topology to 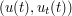 . Thus in turn follows from a fundamental fact (which requires a certain amount of effort to prove) about the PDE to (4), namely that it is well-posed in the energy class. This means that not only do solutions exist and are unique for initial data in the energy class, but they depend continuously on the initial data in the energy topology; small perturbations in the data lead to small perturbations in the solution, or more formally that the map
. Thus in turn follows from a fundamental fact (which requires a certain amount of effort to prove) about the PDE to (4), namely that it is well-posed in the energy class. This means that not only do solutions exist and are unique for initial data in the energy class, but they depend continuously on the initial data in the energy topology; small perturbations in the data lead to small perturbations in the solution, or more formally that the map 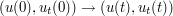 from data to solution (say, at some fixed time t) is continuous in the energy topology. This final fact concludes the limiting argument and gives us the desired conservation law
from data to solution (say, at some fixed time t) is continuous in the energy topology. This final fact concludes the limiting argument and gives us the desired conservation law 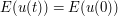 .
.
Example 4: The maximum principle
The maximum principle is a fundamental tool in elliptic and parabolic PDE (for example, it is used heavily in the proof of the Poincaré conjecture, see e.g. my lecture notes on this topic). Here is a model example of this principle:
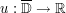 be a smooth harmonic function on the closed unit disk
be a smooth harmonic function on the closed unit disk 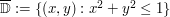 . If M is a bound such that
. If M is a bound such that 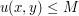 on the boundary
on the boundary 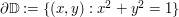 . Then on the interior as well.
. Then on the interior as well.A naive attempt to prove proposition 1 comes very close to working, and goes like this: suppose for contradiction that the proposition failed, thus u exceeds M somewhere in the interior of the disk. Since u is continuous, and the disk is compact, there must then be a point 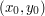 in the interior of the disk where the maximum is attained. Undergraduate calculus then tells us that
in the interior of the disk where the maximum is attained. Undergraduate calculus then tells us that 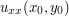 and
and 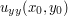 are non-positive, which almost contradicts the harmonicity hypothesis
are non-positive, which almost contradicts the harmonicity hypothesis 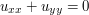 . However, it is still possible that and
. However, it is still possible that and 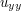 both vanish at , so we don't yet get a contradiction.
both vanish at , so we don't yet get a contradiction.
But we can finish the proof by giving ourselves an epsilon of room. The trick is to work not with the function u directly, but with the modified function 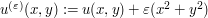 , to boost the harmonicity into subharmonicity. Indeed, we have
, to boost the harmonicity into subharmonicity. Indeed, we have 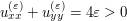 . The preceding argument now shows that cannot attain its maximum in the interior of the disk; since it is bounded by
. The preceding argument now shows that cannot attain its maximum in the interior of the disk; since it is bounded by 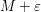 on the boundary of the disk, we conclude that is bounded by
on the boundary of the disk, we conclude that is bounded by 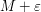 on the interior of the disk as well. Sending we obtain the claim.
on the interior of the disk as well. Sending we obtain the claim.
is a smooth harmonic function on the closed unit disk and 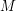 is a bound such that on "near all" the boundary, i.e., in
is a bound such that on "near all" the boundary, i.e., in 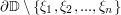 , then on the interior as well. Hint.: Create an epsilon of room with the functions
, then on the interior as well. Hint.: Create an epsilon of room with the functions 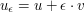 , where
, where 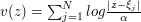 and
and  is a constant greater than 2 (the diameter of
is a constant greater than 2 (the diameter of 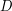 ).
).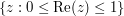 , is bounded in magnitude by 1 on the boundary of this strip, and obeys a growth condition
, is bounded in magnitude by 1 on the boundary of this strip, and obeys a growth condition 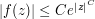 on the interior of the strip, then show that f is bounded in magnitude by 1 throughout the strip. Hint: multiply f by
on the interior of the strip, then show that f is bounded in magnitude by 1 throughout the strip. Hint: multiply f by 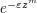 for some even integer m.
for some even integer m.Example 5: Manipulating generalised functions
In PDE one is primarily interested in smooth (classical) solutions; but for a variety of reasons it is useful to also consider rougher solutions. Sometimes, these solutions are so rough that they are no longer functions, but are measures, distributions, or some other concept of "generalised function" or "generalised solution". For instance, the fundamental solution to a PDE is typically just a distribution or measure, rather than a classical function. A typical example: a (sufficiently smooth) solution to the three-dimensional wave equation 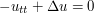 with initial position
with initial position 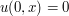 and initial velocity
and initial velocity 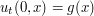 is given by the classical formula
is given by the classical formula
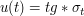
where 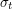 is the unique rotation-invariant probability measure on the sphere
is the unique rotation-invariant probability measure on the sphere 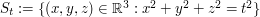 of radius t, or equivalently, the area element dS on that sphere divided by the surface area
of radius t, or equivalently, the area element dS on that sphere divided by the surface area 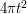 of that sphere. (The convolution
of that sphere. (The convolution 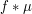 of a smooth function and a (compactly supported) finite measure
of a smooth function and a (compactly supported) finite measure 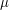 is defined by
is defined by 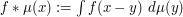 .)
.)
For this and many other reasons, it is important to manipulate measures and distributions in various ways. For instance, in addition to convolving functions with measures, it is also useful to convolve measures with measures; the convolution 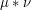 of two finite measures on
of two finite measures on 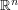 is defined as the measure which assigns to each measurable set E in , the measure
is defined as the measure which assigns to each measurable set E in , the measure
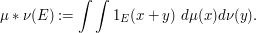
For sake of concreteness, let's focus on a specific question, namely to compute (or at least estimate) the measure 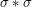 , where is the normalised rotation-invariant measure on the unit circle
, where is the normalised rotation-invariant measure on the unit circle 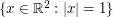 . It turns out that while is not absolutely continuous with respect to Lebesgue measure
. It turns out that while is not absolutely continuous with respect to Lebesgue measure 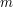 , the convolution is:
, the convolution is: 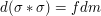 for some absolutely integrable function f on
for some absolutely integrable function f on 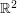 . But what is this function f? It certainly is possible to compute it from the definition (5), or by other methods (e.g. the Fourier transform), but I would like to give one approach to computing these sorts of expressions involving measures (or other generalised functions) based on epsilon regularisation, which requires a certain amount of geometric computation but which I find to be rather visual and conceptual, compared to more algebraic approaches (e.g. based on Fourier transforms). The idea is to approximate a singular object, such as the singular measure , by a smoother object
. But what is this function f? It certainly is possible to compute it from the definition (5), or by other methods (e.g. the Fourier transform), but I would like to give one approach to computing these sorts of expressions involving measures (or other generalised functions) based on epsilon regularisation, which requires a certain amount of geometric computation but which I find to be rather visual and conceptual, compared to more algebraic approaches (e.g. based on Fourier transforms). The idea is to approximate a singular object, such as the singular measure , by a smoother object 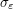 , such as an absolutely continuous measure. For instance, one can approximate by
, such as an absolutely continuous measure. For instance, one can approximate by
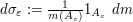
where 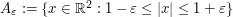 . It is clear that converges to in the vague topology, which implies that
. It is clear that converges to in the vague topology, which implies that 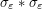 converges to
converges to 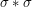 in the vague topology also. Since
in the vague topology also. Since
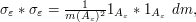
we will be able to understand the limit f by first considering the function
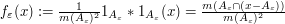
and then taking (weak) limits as to recover f.
Up to constants, one can compute from elementary geometry that 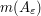 is comparable to , and
is comparable to , and 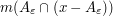 vanishes for
vanishes for 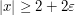 , and is comparable to
, and is comparable to 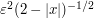 for
for 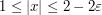 (and of size
(and of size 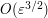 in the transition region
in the transition region 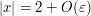 ) and is comparable to
) and is comparable to 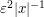 for
for 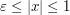 (and of size about
(and of size about 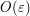 when
when 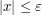 . (This is a good exercise for anyone who wants practice in quickly computing the orders of magnitude of geometric quantities such as areas; for such order of magnitude calculations, quick and dirty geometric methods tend to work better here than the more algebraic calculus methods you would have learned as an undergraduate.) The bounds here are strong enough to allow one to take limits and conclude what f looks like: it is comparable to
. (This is a good exercise for anyone who wants practice in quickly computing the orders of magnitude of geometric quantities such as areas; for such order of magnitude calculations, quick and dirty geometric methods tend to work better here than the more algebraic calculus methods you would have learned as an undergraduate.) The bounds here are strong enough to allow one to take limits and conclude what f looks like: it is comparable to 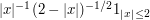 . And by being more careful with the computations of area, one can compute the exact formula for f(x) (more detail needed here).
. And by being more careful with the computations of area, one can compute the exact formula for f(x) (more detail needed here).
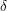 will not give a measure or distribution, because if one looks at the squares
will not give a measure or distribution, because if one looks at the squares 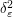 of some smoothed out approximations
of some smoothed out approximations 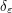 to the Dirac function (i.e. approximations to the identity), one sees that their masses go to infinity in the limit , and so cannot be integrated against test functions uniformly in . On the other hand, derivatives of the delta function, while no longer measures (the total variation of derivatives of become unbounded), are at least still distributions (the integrals of derivatives of against test functions remain convergent).
to the Dirac function (i.e. approximations to the identity), one sees that their masses go to infinity in the limit , and so cannot be integrated against test functions uniformly in . On the other hand, derivatives of the delta function, while no longer measures (the total variation of derivatives of become unbounded), are at least still distributions (the integrals of derivatives of against test functions remain convergent).
Comments
Inline comments
The following comments were made inline in the article. You can click on 'view commented text' to see precisely where they were made.
I find this rather hard to
Tue, 05/05/2009 - 23:50 — gowersI find this rather hard to understand. I also find it difficult to see what it adds to the quick description. Perhaps instead one could have an easy example, such as approximating a function in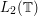 by a trigonometric polynomial by first approximating by a step function, then approximating the step function by a continuous function, and finally approximating the continuous function uniformly by a trigonometric polynomial. The first two steps tell you that you can find a sequence of continuous functions that approximate your function in
by a trigonometric polynomial by first approximating by a step function, then approximating the step function by a continuous function, and finally approximating the continuous function uniformly by a trigonometric polynomial. The first two steps tell you that you can find a sequence of continuous functions that approximate your function in 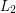 , and the property of being approximable in
, and the property of being approximable in 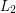 is obviously closed under limits. (Incidentally, I think "closed under limits" would be clearer than "commutes with limits in some sense".
is obviously closed under limits. (Incidentally, I think "closed under limits" would be clearer than "commutes with limits in some sense".
First paragraph
Wed, 06/05/2009 - 00:36 — JoseBroxI'll try to answer:
1. Why exactly do you fin it hard to understand? Is it caused by a word? Should it be wholly rephrased? (English is not my native language, so my writing can be convoluted or even plainly wrong!)
2. What does it add to the quick description? I wanted to make the article more "friendly". I wanted to write one paragraph that an undergraduate could fully understand; I think the quick description is too technical for that level, because understanding it implies being fairly used to "trick thinking" already - and then, at this level the trick is rather obvious!
With this in mind (not everyone who comes here should be used enough to "tricks jargon"!), I included the simplest example because it is conceptually near to the "limiting argument" technique, which I think is well-known for undergraduates.
3. Why don't just have an easy example? Because an example, being as good as any other tool, is not an explanation. Actually, to properly show a general technique, you must give a metaexample (a collection of similar examples or an abstract example), and that's what I tried to do: give this example where the approximation is done just by a sequence and the approximating properties are not just converging to the desired property - they are the very same during all the process.
In my humble opinion, examples should be confined to the "examples" section and the general discussion and quick description should give abstract definitions and metaexamples.
4. Does "closed under limits" really sound clearer in English or is it just "more rigorous"? (I ask because I don't really know!). To me, the idea that the "operators" 'limit' and 'property' conmute looked like the easiest picture to grasp, and I just wanted the general idea to be understood. If an english student would understand better "closed under limits", then change it, please!
Let me try to explain in
Wed, 06/05/2009 - 10:50 — gowersLet me try to explain in detail.
The first, simplest instance of this trick
The word "instance" leads the reader to expect an example – indeed, from what you say, the simplest non-trivial example.
would be
Do you mean "is"?
to prove that an object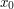 satisfies a property
satisfies a property 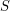 ,
,
Ah – it's not an example after all but a very abstract situation (since the concepts of "object" and "property" are about as general as you can get).
which we know that conmutes with a limit in some sense,
An undergraduate would not be comfortable with this notion of "commutes", and "in some sense" is unnecessarily vague: one should say something more precise, such as "A limit of objects that satisfy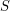 also satisfies
also satisfies 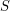 ."
."
by finding a sequence of objects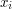 such that
such that 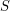 is invariant on it
is invariant on it
The word "invariant" is unnecessarily off-putting. Does this mean just that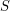 holds for every
holds for every 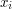 ? Or do you mean that
? Or do you mean that 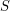 is actually a function that is constant on the
is actually a function that is constant on the 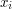 ?
?
and such that it converges (in the same limit sense) to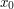 .
.
Ah, now I start to wonder whether "in some sense" above was referring to the limit rather than the commutation. In any case, better to declare right at the start that we think of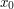 as a limit of the
as a limit of the 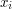 .
.
The power of the method goes in the difficulty of proving the satisfaction of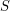 :
: 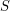 should be easy to prove for every
should be easy to prove for every 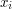 by some standard techniques, but difficult for
by some standard techniques, but difficult for 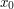 with the same techniques.
with the same techniques.
I'm afraid I completely disagree with you about the status of examples. One example makes this clear, whereas with no examples one might think, "Surely if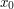 is the limit of the
is the limit of the 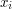 , then the only way of proving that
, then the only way of proving that 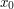 satisfies
satisfies 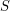 will be along the lines you suggest. So what's the trick here?" Of course, the answer is that you actually construct the sequence, and do so in such a way that it consists of simpler objects (something you don't say here).
will be along the lines you suggest. So what's the trick here?" Of course, the answer is that you actually construct the sequence, and do so in such a way that it consists of simpler objects (something you don't say here).
Note that this instance is somewhat the "reciprocal" of a limiting process (where we replace a sequence by its limit).
I don't really see what you're getting at here.
But of course,
If you're talking to undergraduates, then you shouldn't say "of course" about something like this.
we don't need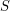 to be invariant in the sequence: we just need to have a perturbed property
to be invariant in the sequence: we just need to have a perturbed property 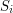 for every
for every 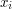 such that
such that 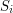 converges to
converges to 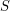
Without an example, what undergraduate will know what you mean by a sequence of properties converging to another property?
as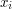 converges to
converges to 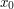 . Moreover, we don't need the index set to be countable: we can use a net; for example, we can indize with the reals and use the variable
. Moreover, we don't need the index set to be countable: we can use a net; for example, we can indize with the reals and use the variable  .
.
This is also not a suitable remark for a "friendly" introduction!
Incidentally, I agree that the existing quick description is a little bit sophisticated for an undergraduate. My solution would probably be to start with a simple example, then continue with a more abstract definition of that example, then give the table, and then give the existing examples.
Inline comments
The following comments were made inline in the article. You can click on 'view commented text' to see precisely where they were made.
Any chance of telling us what
Wed, 06/05/2009 - 12:08 — gowersAny chance of telling us what these principles are? I probably ought to know, but I don't, and maybe others don't either.
Article has been truncated
Wed, 05/01/2011 - 16:44 — taoFor some strange reason, all revisions of this article have been truncated at the first paragraph, and I cannot find a way to retrieve any subsequent portion of the text. Has this also occurred for other articles? Is there any way to recover some copy of the full article?
Article restored
Mon, 10/01/2011 - 09:08 — olofA few other articles had also been mysteriously truncated, but I have now restored them (and this one). If anyone spots another page that does not look right then please let us know, for example via the forums.
Post new comment
(Note: commenting is not possible on this snapshot.)