Quick description
This article gives an introductory description of probability theory and links to Tricki articles on methods of this field.
General discussion
 |
In mathematics and its applications it often makes sense to assign weights to elements of a set of interest. A weight can mean many things, for example, the statistical frequency of an observation of a random outcome, allocation of a resource or the degree of belief in an outcome. Then a typical problem is to compute the total weight of a subset of elements. Probability theory studies this and related problems, the ways one can assign weights to various sets and how these weights transform as the sets on which they are defined are transformed.
The concept that precisely defines the idea of assigning generalized weights to sets is that of a measure. A probability measure is a nonnegative measure with total measure 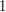 .
.
In probability theory measurable functions are called random variables. An integral against a probability measure is called an expectation.
|
The main areas of study in probability theory are:
-
Construction: how to define and characterize probability measures,
-
Transformations of probability measures,
-
Convergence:
-
Given a sequence of probability measures or random variables, what are the possible ways for this sequence to converge?
-
In case of taking limits of measures, what are the possible limit measures?
-
How to characterize and check convergence?
-
Analysis of the speed of convergence,
-
Asytmptotics of expectations,
-
-
Computation of probabilites and expectations,
-
Bounding probabilities and expectations,
-
Optimizing probabilities and expectations,
-
Min/Max problems involving expectations.
Probability theory also studies the structure of probability measures. In particular, the theory of stochastic processes, i.e., the study of measures on spaces of functions of a real or an integer variable, is very advanced.
This page contains links to more specific navigational pages devoted to probability.
Comments
Inline comments
The following comments were made inline in the article. You can click on 'view commented text' to see precisely where they were made.
I don't like this first
Fri, 24/04/2009 - 00:14 — gowersI don't like this first sentence, for two reasons.
1. I disagree with it. I think probability theory is the study of ... probabilities, and probability measures are how we formulate that in a rigorous way. (For example, one would never say, "Number theory is the study of finite sets that are transitive and totally ordered by inclusion." Rather, it's the study of numbers and their relationships, and it so happens that we (sometimes) model numbers with the help of set theory.)
2. It will put off many readers. There will be lots of probability articles on the Tricki that will be comprehensible to someone who knows no measure theory, and they won't all be elementary.
A slightly more subtle objection (to the second paragraph) is that I don't like the identification of random variables with measurable functions. This is a point that was made to me by a probabilist who wrote for the Princeton Companion to Mathematics: almost all the time, one can analyse random variables without having to worry about what sample space one is using, and this is the "correct" way to think probabilistically.
Having said that, there is a place for the view of probability that you are putting forward here – as a sort of branch of measure theory. Perhaps there should be a measure theory front page with a subpage devoted to probability measures.
I'm not making any changes at the moment, partly because of time constraints and partly because others may wish to express their views before I go ahead and do anything.
probability
Fri, 24/04/2009 - 02:10 — devinThanks for the comment. I do hope that you and others will feel free to edit any of what I wrote here, I understand that it can be written better.
On the issue of what is probability theory I would like to share a sentence from Doob from his book Stochastic Processes:
``Probability is simply a branch of measure theory, with its own special emphasis and field of application, and no attempt has been made to suger-coat this fact. (page 1)''
Your point about the first sentence being incomplete and dry, I do agree. I couldn't come up with something better at a first writing. Here is again a better statement by Doob, which, similar to your sentence, emphasizes the relations rather than the objects:
``The theory of probability is concerned with the measure properties of various spaces, and with the mutual relations of measurable functions defined on those spaces. (Stochastic processes, page 2).''
random variables
Fri, 24/04/2009 - 03:09 — devinI think the identification of random variables and measurable functions is standard. For example, Varadhan's Probability Theory book, page 7:
``An important notion is that of a random variable or a measurable function.''
then the next definition:
``Definition 1.5. A random variable or a measurable function is a map ...''
Another example is the book Probabilities and Potential by [[w:Paul-Andr
Actually, my view is more
Fri, 24/04/2009 - 08:08 — gowersActually, my view is more nuanced than my last comment would suggest. Having just taught a probability course, I think that one should define a random variable as a (measurable – though I prefer to start with the discrete case) function on a probability space, one should try as hard as possible not to use this in proofs. It's very convenient to use it when proving linearity of expectation, but for most other things one can avoid mentioning the sample space. Perhaps I'll write a Tricki article called something like "How not to think about sample spaces."
more on random variables
Fri, 24/04/2009 - 17:47 — devinI think we have similar views on these things. My guess is what you refer to as the sample space in your statement ``...but for most other things once can avoid mentioning the sample space'' is the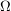 in, for example, the following statement:
in, for example, the following statement:
``Let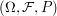 be a probability space and let
be a probability space and let 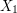 ,
, 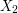 , ...,
, ...,  ,... be a sequence of iid Bernoulli random variables with
,... be a sequence of iid Bernoulli random variables with 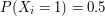 ''
''
Unfortunately, it is common in probability to state the structures that underly the problem in this abstract and obscure way. What is the remedy? I think the remedy is to explicitly state what these things are for the problem at hand. For example, I would rewrite the above statement as follows: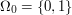 and
and 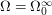 .
.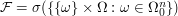 .
.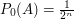 for
for 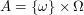 ,
, 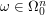 and let
and let 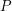 be the unique extension of
be the unique extension of 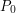 to
to 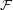 . Let
. Let 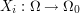 be the coordinate projections.''
be the coordinate projections.''
``
Let
Let
Define
One can write it in different ways but the point is: explicitly state what your maps are, what your sigma algebras are.
I think that the concepts of sigma algebras, measurability, maps, etc. are very well thought abstractions that are useful at every level, including, finite sets. If for nothing else, for notational and pedagogical reasons. For example: the notation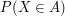 is good, it allows us to talk about the result
is good, it allows us to talk about the result 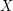 of an experiment. How to make this notation meaningful? Here is an example: If the experiment is the throw of a die, then
of an experiment. How to make this notation meaningful? Here is an example: If the experiment is the throw of a die, then 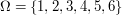 ,
,  and finally the random variable is
and finally the random variable is 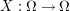 ,
, 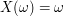 is simply the canonical map. Is this abstract nonsense? I don't think so. Now I can soundly write
is simply the canonical map. Is this abstract nonsense? I don't think so. Now I can soundly write 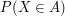 .
.
Philosophically, I find this setup meaningful as well.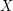 is the identity map. Why? Because we model the experiment as random, i.e., we have settled to accept that we don't know the causes that determine the outcomes of the roll of our die. If we did then the causes would have been the domain of
is the identity map. Why? Because we model the experiment as random, i.e., we have settled to accept that we don't know the causes that determine the outcomes of the roll of our die. If we did then the causes would have been the domain of 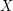 and
and 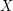 would actually be a function mapping the causes to the effects. We throw away the causes and the relation between the causes and the effects and define
would actually be a function mapping the causes to the effects. We throw away the causes and the relation between the causes and the effects and define 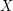 as a map that maps each effect to itself. And as far as our knowledge of the experiment goes, we settle to simply live with the statistical properties of the outcomes, which we represent as a probability distribution.
as a map that maps each effect to itself. And as far as our knowledge of the experiment goes, we settle to simply live with the statistical properties of the outcomes, which we represent as a probability distribution.
From the pedagogical point of view: I ask my students nontrivial measurability questions in finite setups so that they get a good sense of what measurability means in cases where they can explicitly write down the objects they are working on. I think this is good preparation for times when one has to think about measuribility in much more abstract circumstances.
The question here is not what
Tue, 28/04/2009 - 12:17 — gowersThe question here is not what the correct way is of setting up a rigorous theory of probability (either for the purposes of research or for the purposes of giving a lecture course on the subject) but rather what is the best thing to put on a probability front page that is intended to help people find ways of solving probabilistic problems.
Suppose that I have a problem in discrete probability: to prove, say, that if I toss a coin 100 times then I have a very high probability of getting at least 30 heads. And suppose I come to the Tricki for help and visit the probability front page. As it is written at the moment, I would be terrified: if I needed help with that kind of problem, then I probably wouldn't know any measure theory, but the clear impression I would get from the page was that measure theory was an essential prerequisite.
I do not object to the content, but merely to its place in the Tricki hierarchy. I think a more obvious organization would be as follows. One begins with an informal description of probability theory, mentioning simple problems about calculating and estimating probabilities. One then explains that the intuitive view of probability has important limitations, and that a modern theory of probability makes heavy use of measure theory. And one then has links to more specialized pages such as elementary probability (essentially just counting problems), discrete probability, and general measure-theoretic probability. That way, the reader interested in problems about particular kinds of convergence of random variables would go to the advanced page, and the reader interested in the probability of getting all four aces in a bridge hand would go to the elementary page, and nobody would be frightened off.
A question that would have to be considered is how much of the basic theory of probability actually belongs on the Tricki. The default would be not much: you assume that the reader knows the basics and the Tricki articles are there to help him/her solve problems.
Added later: an interesting comparison can be drawn with the Wikipedia introduction to probability, which is more in the style that I would expect for a Tricki front page (though it wouldn't be perfect because it is not focused on problem-solving in quite the right way).
I think that Tim's
Tue, 28/04/2009 - 15:56 — emertonI think that Tim's suggestions make good sense. The measure-theoretic foundations for probability are needed for studying sophisticated questions, but there are lots of elementary quesitons in probability theory that are basically questions of counting, and it would for a reader to the tricki to be able to reach them in the tree structure without having to go through measure theory first.
Related to an earlier comment: here is my guess as to what it might mean to avoid referring to the sample space:
If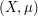 is a probability space and
is a probability space and 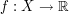 a random variable,
a random variable,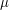 via
via 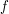 , to get a meausre on
, to get a meausre on 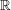 :
: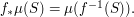 Now one frequently
Now one frequently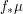 is absolutely continuous with respect to Lebesque measure, and so can be written in the form
is absolutely continuous with respect to Lebesque measure, and so can be written in the form 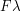 , where
, where 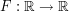 is a function and
is a function and 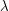 denotes Lebesgue measure.
denotes Lebesgue measure.
then we can push-forward the meausre
the push-forward is defined by
finds that
I guess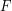 is the probability distribution of the random variable
is the probability distribution of the random variable 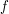 .
.
Now one can try to study and answer as many questions as possible just in terms of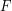 , and my impression is that many results in probability theory proceed along these lines: one has a (or perhaps a sequence) of random variables satisfying certain restrictions on their distribution, and one draws some conclusion about the random variable, or about some kind of normalized limit of the sequence. (I am thinking say of the central limit theorem.) In these theorems the particular sample space doesn't really play any role, as far as I know; one can just argue with the distributions (or more abstractly, and perhaps more generally, with the push-forward measures attached to the random variables).
, and my impression is that many results in probability theory proceed along these lines: one has a (or perhaps a sequence) of random variables satisfying certain restrictions on their distribution, and one draws some conclusion about the random variable, or about some kind of normalized limit of the sequence. (I am thinking say of the central limit theorem.) In these theorems the particular sample space doesn't really play any role, as far as I know; one can just argue with the distributions (or more abstractly, and perhaps more generally, with the push-forward measures attached to the random variables).
It is, I would think, an important point to know that often one doesn't really have to understand the full details of the sample space, but rather, just the distribution of the random variable one is studying. (In practical terms, the latter is at least in principle capable of being measured, while the sample space might be completely inaccessible.)
One suggestion is to begin with a more intuitive discussion of probability on the front page. One could define a random variable as being a quantity, that varies randomly, and that one wants to study (e.g. sum of the faces of two rolled dice, height of a random American, ...). It would be good to emphasize that random variables can be discrete (the dice example) or continuous (the height example).
We could then explain that a random variable has a distribution, which basically governs its behaviour. (And again this could be illustrated with the examples.) In general, emphasizing that there are some very common and important distributions, e.g. binomial, normal, Poisson, would be good.
Next could come the discussion of how this is mathematically modelled, with the idea being that simple models suffice for easy discrete questions like rolling a pair of dice, that more analysis is needed for studying continuous random variables, and that the general foundations rely on measure theory, etc.
Then we could begin with links to various subpages, with appropriate commentary. One page could be rigorous foundations of probability, which is where the current discussion of measure spaces, random variables as meausrable functions, etc., would live.
Thanks for the comments. My
Tue, 28/04/2009 - 18:55 — devinThanks for the comments. My goal in writing the things I wrote here was a succint classification of the central problems that people study in probability theory. I thought such a classification would allow someone to easily locate a technique of interest.
I think we all agree that the front page can be made more lively and less technical.
Here are few points on some of your comments:
Being terrified by the word
Tue, 28/04/2009 - 20:19 — wiltonBeing terrified by the word measure is I think as reasonable as being terrified by the words `group' or `ideal.'
But the fact remains that it is possible to ask questions about probability without knowing what a measure is. And this is the probability front page.
If you go to the Group Theory front page, you'll see that it starts with a (brief) attempt to explain that the notion of group formalizes the notion of symmetry. So anyone who has a question about symmetry will perhaps be able to figure out that they need to start thinking about groups. Something similar should apply here.
> Now one can try to study
Tue, 28/04/2009 - 19:55 — devin> Now one can try to study and answer as many questions as possible just in terms
> of , and my impression is that many results in probability theory proceed along
> these lines: one has a (or perhaps a sequence) of random variables satisfying
> certain restrictions on their distribution, and one draws some conclusion about
> the random variable, or about some kind of normalized limit of the sequence. (I
> am thinking say of the central limit theorem.) In these theorems the particular
> sample space doesn't really play any role, as far as I know; one can just argue
> with the distributions (or more abstractly, and perhaps more generally,
> with the push-forward measures attached to the random variables).
> It is, I would think, an important point to know that often one doesn't really > have to understand the full details of the sample space, but rather, just the
> distribution of the random variable one is studying.
Once again, we are in agreement, but let's be careful about what the random variables and their distributions are.
Let's look at the example you gave, the central limit theorem. What is this theorem about?
Suppose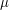 is a probability measure on
is a probability measure on 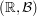 with unit second moment, i.e.,
with unit second moment, i.e., 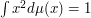 and zero mean, i.e.,
and zero mean, i.e., 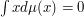 . Here
. Here 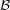 is the borel sigma field. Let
is the borel sigma field. Let 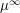 be the product measure on
be the product measure on 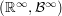 . Let
. Let 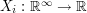 be the coordinate maps. Let
be the coordinate maps. Let 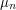 be the measure defined on
be the measure defined on 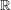 by the map
by the map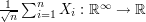 . The central limit theorem states that
. The central limit theorem states that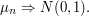
This explicit way of writing things makes it clear that the central limit theorem is a statement not about real random variables and their distributions but about product probability measures on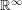 and the transformation of such measures under summation and scaling. As you said, there could have been even a larger space
and the transformation of such measures under summation and scaling. As you said, there could have been even a larger space 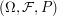 on which
on which 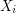 were defined. In that case one first pushes the measure forward onto
were defined. In that case one first pushes the measure forward onto 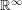 using the map
using the map 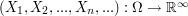 .
.
Added later: Another point of view, for this problem, is to think only about the pair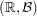 and a measure
and a measure 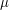 on this pair with the above mentioned properties. We then define
on this pair with the above mentioned properties. We then define 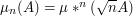 , where
, where 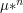 is the convolution of
is the convolution of 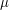 with itself
with itself  times. The CLT says
times. The CLT says  . . This point of view is also the one that quickly suggests the most well known proof of this result: take Fourier transforms and study their limits. Most generalizations though will involve measures on
. . This point of view is also the one that quickly suggests the most well known proof of this result: take Fourier transforms and study their limits. Most generalizations though will involve measures on 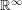 or larger sets.
or larger sets.
I guess, I made my point thoroughly :) I find it extremely useful to state the sets and the measures I am using and focusing on these and thinking about methods in terms of these. I am completely open to other ways of thinking, especially from the point of view of writing tricki articles. Sorry if I took too long in expressing my thoughts. Many thanks again for your thoughts!
Thanks for your reply. I
Wed, 29/04/2009 - 04:27 — emertonThanks for your reply. I think its helpful to explain our various points of view. I'm going to write a little more about mine; it is a little redundant, given what I've already written, but perhaps it will put my thoughts in a larger context than just the probability page.
I think that one thing that is helpful to think about in preparing tricki pages, and especially the top-level pages, is who the possible audience will be, and what they should be getting out of their tricki experience. (My impression is that this is every much in Tim's mind as he writes his articles and comments.)
There are some areas of math which I would say are almost purely technical, and where it is reasonable to expect a certain level of mathematical competence of the reader. For example, How to use spectral sequences (a page that I hope to eventually write, if someone doesn't beat me to it) is unlikely to be studied by anyone who doesn't have a solid undergraduate background in algebra, and probably some graduate training in algebra and or topology as well. Spectral sequences are really an intrinsically technical tool. They are important (and so I think they merit a tricki page, especially because many grad students suffer in learning to use them, and any additional help and explanation will, I expect, be welcomed by many), but are not a fundamental topic in mathematics, of interest to those who are not working mathematicians, or aspiring to become such.
On the other hand, one can expect that the Diophantine equations front page, when it is written, to be of much broader interest. Diophantine equations are a central topic in mathematics, and of interest to a broad range of people: amateurs, students involved in the maths olympiad or similar competitions, undergraduates, and of course graduate students and professional mathematicians. There is a lot that one can say technically about Diophantine equations: one can talk about Galois cohomology, and how this plays a key role; also modular, or more generally automorphic forms, and the Langlands program; the Hasse principle,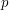 -adic numbers and adeles;
-adic numbers and adeles; 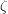 - and
- and  -functions; the circle method; and so on. These are all central ideas in the modern theory of Diophantine equations. But I don't think that they should be the focus of the Diophantine equations front page; they will be outside the technical range of many visitors to the page, and there will be much of interest that can be said about Diophantine equations that will be accessible to these visitors — but only if it is couched in less technical language. Furthermore, writing things in as accessible way as possible will help professional mathematicians as well: no doubt there will be mathematicians reading the Diophantine equations front page, once it exists, whose own area of expertise will be far from number theory; using the bare minimum of technical language required for any particular example or technique will make it much easier for them to extract utility from the tricki.
-functions; the circle method; and so on. These are all central ideas in the modern theory of Diophantine equations. But I don't think that they should be the focus of the Diophantine equations front page; they will be outside the technical range of many visitors to the page, and there will be much of interest that can be said about Diophantine equations that will be accessible to these visitors — but only if it is couched in less technical language. Furthermore, writing things in as accessible way as possible will help professional mathematicians as well: no doubt there will be mathematicians reading the Diophantine equations front page, once it exists, whose own area of expertise will be far from number theory; using the bare minimum of technical language required for any particular example or technique will make it much easier for them to extract utility from the tricki.
Probability is similar: it is a fundamental topic in mathematics. It is not a purely technical subject, but rather is of interest to a very wide range of people, from those interested in elementary calculations, to those interested in substantial applications (to the real world, or perhaps to problems in other parts of mathematics), to those interested in the theory itself for its own sake.
We will want the tricki page to be as accessible to as many of these people as possible; not all of them will know measure theory, and there will be many examples that they can understand despite this, if we write them in an a certain way.
I don't think that every example should be requried to use the absolutely minimal amount of machinery necessary to make it tick; indeed, some examples will have as their point the illustration of how to use a particular piece of machinery or advanced technique in a simple situation (as part of an explanation of how to use that piece of machinery or technique). But I don't believe that we want every example to be burdened by machinery, especially in broad topics of wide interest such as probability or number theory. And a logical consequence of this belief is that the top level introductions to these topics shouldn't themselves be entirely enmeshed in machinery and technical language. They should allow for multiple viewpoints on their topic, both elementary and advanced.
I will close by emphasizing that I am very far from an expert in probability, so I don't think that I will actually be contributing much to the probability branches of the tricki tree. On the other hand, I do hope to learn from it as it grows (and perhaps improve my understanding of measure theory in the process!).
how to write a tricki article
Tue, 12/05/2009 - 16:30 — devinThank you. I will try to follow your thoughts here as I contribute to tricki articles.
A suggestion: a new article in the `help' section on `how to write tricki articles'
Post new comment
(Note: commenting is not possible on this snapshot.)