Quick description
If you are hoping to use the probabilistic method as part of a long and complicated proof, you will probably want to begin by producing a plausible sketch of the argument before you go into the technical details. For this purpose it is very useful to be able to guess upper (and sometimes lower) bounds for the probabilities of various complicated events. This article discusses heuristic principles that can help one do this, and illustrates them with examples.
 |
Principle 1: pretend your variables are independent
This is the single most useful method for guessing probabilistic bounds: if you have some variables that exhibit a reasonable degree of independence, then they will probably give estimates that are very similar to the ones that would apply if they actually were independent. Of course, one needs to be clear about what "reasonably independent" might mean, so let us look at a few examples.
Example 1
Let 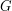 be a random graph with
be a random graph with  vertices in which each edge is chosen independently with probability
vertices in which each edge is chosen independently with probability 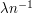 . Let
. Let  be the number of triangles in . Then is a random variable: how should we expect to be distributed?
be the number of triangles in . Then is a random variable: how should we expect to be distributed?
Given any triangle 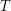 in the complete graph on the vertices of , then will belong to with probability
in the complete graph on the vertices of , then will belong to with probability 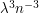 . The number of such triangles is
. The number of such triangles is 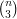 , which is about
, which is about 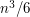 , so the expectation of is about
, so the expectation of is about 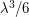 . Also, if
. Also, if 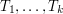 are disjoint triangles, then the events "
are disjoint triangles, then the events "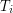 belongs to " are independent; and a typical pair of triangles will be disjoint.
belongs to " are independent; and a typical pair of triangles will be disjoint.
It is clear then that we have a lot of independence about. What would happen if the events "triangle belongs to " were all independent? Then would be a sum of Bernoulli random variables, each with probability . In other words, it would be counting the number of occurrences when you have lots of independent unlikely events. The probability distribution that's appropriate for this is the Poisson distribution, so we might guess that is distributed roughly like a Poisson random variable of mean .
This is not a proof of course, and it turns out to be a hard problem to determine the distribution of . Nevertheless, the exercise of pretending that the events are independent is a helpful one: it gives us some idea what to expect, and it also gives us a starting point if we want to prove it. (The starting point would be the thought that we could look very carefully at the proof that is approximately Poisson when the events are independent and try to relax the assumptions we make, allowing a small amount of dependence. And there are indeed important proofs like this in probabilistic combinatorics: see Janson's inequality, for instance.)
Example 2
A certain amount of care is needed even when one is just guessing. For instance, suppose we tried to use the same reasoning to count the number of copies of a graph 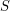 that consists of five vertices
that consists of five vertices 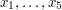 with the first four all joined to each other and the fifth one joined just to the fourth (so has seven edges). And suppose that the edges of have been chosen with probability
with the first four all joined to each other and the fifth one joined just to the fourth (so has seven edges). And suppose that the edges of have been chosen with probability 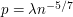 . The expected number
. The expected number  of copies of is about
of copies of is about 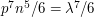 (the factor of
(the factor of 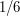 is there because has a symmetry between three of its vertices). So do we expect the distribution of to be approximately Poisson with mean
is there because has a symmetry between three of its vertices). So do we expect the distribution of to be approximately Poisson with mean 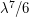 ?
?
To see that we don't, note that the expected number of copies of 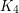 in is
in is 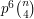 , which is about
, which is about 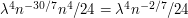 . In other words, it is far less than 1 (for fixed
. In other words, it is far less than 1 (for fixed 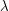 and large ). What this implies is that although the expected number of copies of is , the norm is to get no copies at all, and just occasionally you get a with a huge number of extra edges joined to its vertices forming copies of .
and large ). What this implies is that although the expected number of copies of is , the norm is to get no copies at all, and just occasionally you get a with a huge number of extra edges joined to its vertices forming copies of .
Example 3
Let us return to triangles, but this time let us take a much larger value of 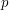 . Indeed, let us take to be independent of . The expected number of triangles is
. Indeed, let us take to be independent of . The expected number of triangles is 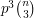 . How about the variance? Well, for any triple
. How about the variance? Well, for any triple 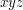 of vertices, let
of vertices, let 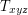 be the event that these vertices form a triangle in the graph. If two triples are disjoint or overlap in just one vertex, then the corresponding events are independent. Given two triples and
be the event that these vertices form a triangle in the graph. If two triples are disjoint or overlap in just one vertex, then the corresponding events are independent. Given two triples and 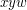 , the probability of and
, the probability of and 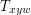 both occurring is
both occurring is 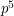 . The number of such pairs of triples is less than
. The number of such pairs of triples is less than 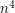 , so this implies that the expectation of the square of the number of events that occur is at most
, so this implies that the expectation of the square of the number of events that occur is at most 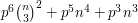 .
.
We see from this that the main contribution to the variance of the number of triangles comes from the term that is proportional to  . What heuristic model could explain this? We clearly cannot pretend that all the events are independent, since then we would have a variance more like
. What heuristic model could explain this? We clearly cannot pretend that all the events are independent, since then we would have a variance more like 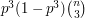 . (This is the variance of the binomial distribution with parameters and
. (This is the variance of the binomial distribution with parameters and 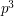 .)
.)
One way of making a better guess is to count first how many edges there are in the graph, and then count the number of triangles based on each edge, treating these numbers as independent. That gives us about 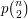 edges, and each edge is the base of a number of triangles that is distributed binomially with parameters
edges, and each edge is the base of a number of triangles that is distributed binomially with parameters 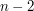 (which we can approximate by ) and
(which we can approximate by ) and 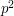 . If we pretend that the numbers of triangles based on the different edges are independent, then we are looking at a sum
. If we pretend that the numbers of triangles based on the different edges are independent, then we are looking at a sum 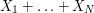 , where the
, where the 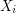 are independent binomial random variables with parameters and , and
are independent binomial random variables with parameters and , and 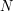 is a binomial with parameters
is a binomial with parameters 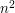 and .
and .
A standard fact about this sort of situation is that the variance is 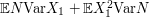 , which gives us about
, which gives us about 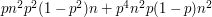 , which is much more like what we actually observe. This suggests that we may have found a good model for what is happening.
, which is much more like what we actually observe. This suggests that we may have found a good model for what is happening.
Comments
Post new comment
(Note: commenting is not possible on this snapshot.)