- Quick description
- Example 1: sums of binomial coefficients
- Example 2: counting the edges of an icosahedron
- General discussion
- Example 3: the sizes of upper shadows
- Example 4: the Erdős-Ko-Rado theorem
- Example 5: an identity concerning Euler's totient function
- Example 6: evaluating zeta(2)
- Another point of view
- Example 7: fixed points and orbits of group actions
Quick description
If you have two ways of calculating the same quantity, then you may well end up with two different expressions. If these two expressions were not obviously equal in advance, then your calculations provide a proof that they are. Moreover, this proof is often elegant and conceptual. Double counting can also be used to prove inequalities, via a simple result about bipartite graphs.
Example 1: sums of binomial coefficients
Prove that 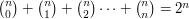 .
.
The left-hand side of this well-known identity counts all the subsets of size 0 from a set of size  , then all the sets of size 1, then all the sets of size 2, and so on. By the time it has finished, it has counted all the subsets of a set of size . But an entirely different argument shows that the number of subsets of a set
, then all the sets of size 1, then all the sets of size 2, and so on. By the time it has finished, it has counted all the subsets of a set of size . But an entirely different argument shows that the number of subsets of a set 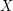 of size is
of size is 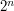 : for each element
: for each element 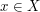 there are two possibilities:
there are two possibilities:  belongs to the subset or does not belong to the subset. Therefore, in determining a subset of we have independent binary choices, so possibilities. (If this argument sounds a bit woolly, then you can prove it by induction. Let be the set
belongs to the subset or does not belong to the subset. Therefore, in determining a subset of we have independent binary choices, so possibilities. (If this argument sounds a bit woolly, then you can prove it by induction. Let be the set 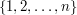 . Then every subset of is obtained by taking a subset of
. Then every subset of is obtained by taking a subset of 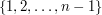 and either adding to it or leaving it alone. Therefore, the number of subsets of is twice the number of subsets of . And the number of subsets of
and either adding to it or leaving it alone. Therefore, the number of subsets of is twice the number of subsets of . And the number of subsets of 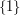 is 2.)
is 2.)
Example 2: counting the edges of an icosahedron
Prove that the number of edges of an icosahedron is 30.
The idea of this example is to deduce the answer very simply from just the fact that an icosahedron has 20 triangular faces. The rough idea of the proof is that each face has three edges, while each edge is an edge of two faces, so the ratio of faces to edges ought to be 2 to 3. To be sure that this argument is correct, we count pairs 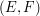 , where
, where 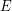 is an edge and
is an edge and 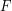 is a face that has as one of its edges. Since the icosahedron has 20 triangular faces, the number of such pairs is 60. If
is a face that has as one of its edges. Since the icosahedron has 20 triangular faces, the number of such pairs is 60. If 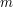 is the number of edges, then the number of such pairs is also
is the number of edges, then the number of such pairs is also 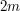 , since each edge is part of two faces. Therefore,
, since each edge is part of two faces. Therefore, 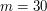 , as claimed.
, as claimed.
General discussion
Many combinatorial applications of the double-counting principle can be regarded as consequences of the following very simple result about bipartite graphs: if 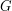 is a bipartite graph with vertex sets and
is a bipartite graph with vertex sets and 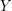 , then the sum of the degrees of the vertices in is equal to the sum of the degrees of the vertices in . The proof is a very simple double count, since the two sums are different ways of counting the edges in (one by focusing on the vertex in and the other by focusing on the vertex in ).
, then the sum of the degrees of the vertices in is equal to the sum of the degrees of the vertices in . The proof is a very simple double count, since the two sums are different ways of counting the edges in (one by focusing on the vertex in and the other by focusing on the vertex in ).
For instance, for the icosahedron we could define a bipartite graph where one vertex set consisted of the edges of the icosahedron and the other of the faces, joining an edge to a face if the edge belonged to the face. The edges of this bipartite graph are precisely the edge-face pairs considered above (so this is not a different proof, but a different way of looking at the same proof).
The following equivalent reformulation of the bipartite-graphs principle can often be used very directly: if 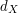 is the average degree of the vertices in and
is the average degree of the vertices in and 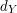 is the average degree of the vertices in , then
is the average degree of the vertices in , then 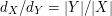 .
.
Many applications of the principle use the following consequence. Let be a bipartite graph with vertex sets and . Suppose that every vertex in has degree and every vertex in has degree . Let 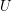 be any subset of , and let
be any subset of , and let 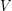 be the set of all vertices in that are joined to at least one vertex in . Then
be the set of all vertices in that are joined to at least one vertex in . Then 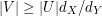 . To prove this, let
. To prove this, let 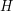 be the subgraph of with vertex sets and , with the edges inherited from . Then every vertex in has degree and every vertex in has degree at most .
be the subgraph of with vertex sets and , with the edges inherited from . Then every vertex in has degree and every vertex in has degree at most .
It often happens that we are in the following situation. We have a set whose size we are trying to bound above, but we do not have an obvious bipartite graph to which to apply an inequality such as the one in the last paragraph. In that case, we must construct one. It is often easier to think about the task in an equivalent way: given a bipartite graph with vertex sets and , each vertex 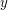 in determines a neighbourhood
in determines a neighbourhood 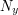 (defined to be the set of all vertices in that are joined to ), and therefore the bipartite graph itself determines a collection of subsets of , possibly with repeats, so strictly speaking it determines a multiset of subsets of . Conversely, given a collection of subsets of , we can use it to define a bipartite graph, by choosing for each set in the collection a vertex (or set of vertices), and putting these vertices together to form a set . This thought leads to another principle. Let
(defined to be the set of all vertices in that are joined to ), and therefore the bipartite graph itself determines a collection of subsets of , possibly with repeats, so strictly speaking it determines a multiset of subsets of . Conversely, given a collection of subsets of , we can use it to define a bipartite graph, by choosing for each set in the collection a vertex (or set of vertices), and putting these vertices together to form a set . This thought leads to another principle. Let 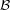 be a collection of subsets of . If each element of is contained in at least sets in and each set in contains at most
be a collection of subsets of . If each element of is contained in at least sets in and each set in contains at most 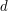 elements of , then
elements of , then 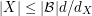 . (To prove this directly, count pairs
. (To prove this directly, count pairs 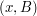 , where ,
, where , 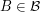 , and
, and 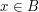 .)
.)
Example 3: the sizes of upper shadows
Let 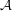 be a collection of subsets of , with every set in of size
be a collection of subsets of , with every set in of size  . Let
. Let 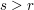 and define the
and define the  -upper shadow
-upper shadow 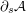 to be the collection of all sets of size that contain at least one set in . Then the size of is at least
to be the collection of all sets of size that contain at least one set in . Then the size of is at least 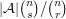 .
.
To prove this assertion, let us define a bipartite graph with vertex sets and , joining 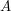 to
to 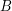 if and only if
if and only if 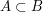 . Then each
. Then each 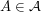 has degree
has degree 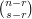 , so in particular this is the average degree. And each
, so in particular this is the average degree. And each 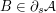 has degree at most
has degree at most 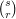 , so this is an upper bound for the average degree of vertices in . By the bipartite-graphs principle, it follows that the size of is at least
, so this is an upper bound for the average degree of vertices in . By the bipartite-graphs principle, it follows that the size of is at least 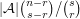 . (Here we have applied the first reformulation of the principle, but we could have applied the second one even more directly.)
. (Here we have applied the first reformulation of the principle, but we could have applied the second one even more directly.)
One can check by direct calculation that 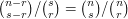 . Here is a double-counting argument instead, which shows that
. Here is a double-counting argument instead, which shows that 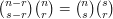 . This time we are not presented with an obvious bipartite graph, so let us look at the right-hand side and see what it might be counting. The first term counts subsets of size from a set of size , and the second counts subsets of size from a set of size . So we could regard the product as the number of ways of choosing a set of size from the set and then choosing a subset of of size .
. This time we are not presented with an obvious bipartite graph, so let us look at the right-hand side and see what it might be counting. The first term counts subsets of size from a set of size , and the second counts subsets of size from a set of size . So we could regard the product as the number of ways of choosing a set of size from the set and then choosing a subset of of size .
Now another way of choosing such a pair 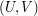 is to choose first. We can do this in
is to choose first. We can do this in 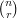 ways, and then there will be
ways, and then there will be 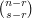 ways of choosing a set of size that contains , since we need to choose
ways of choosing a set of size that contains , since we need to choose  more elements from the
more elements from the 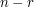 elements we still have left.
elements we still have left.
Example 4: the Erdős-Ko-Rado theorem
Let be a collection of subsets of such that every has size and such that no two sets in are disjoint. Suppose also that 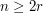 . Then
. Then 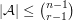 .
.
Note that the collection of all sets of size that contain the element 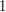 has size
has size 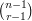 , so this result is best possible. Note also that
, so this result is best possible. Note also that 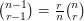 , so what we are trying to show is that the proportion of sets of size that we can choose if no two are disjoint is at most
, so what we are trying to show is that the proportion of sets of size that we can choose if no two are disjoint is at most 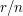 . Thirdly, note that if
. Thirdly, note that if 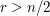 then any two sets of size intersect, so that condition is necessary. For convenience, let us us the standard notation
then any two sets of size intersect, so that condition is necessary. For convenience, let us us the standard notation ![[n]](../images/tex/de504dafb2a07922de5e25813d0aaafd.png) for the set and
for the set and ![[n]^{(r)}](../images/tex/14d3ec1418bb8a33eeac1817c9ac3a0c.png) for the collection of subsets of of size . Also, we shall call a set system in which any two sets have non-empty intersection an intersecting system.
for the collection of subsets of of size . Also, we shall call a set system in which any two sets have non-empty intersection an intersecting system.
To solve this problem let us try to find a collection  of subsets of with the following three properties. First, if is any element of (note that we have three levels of sets here, so an element of is a subset of and therefore a collection of subsets of ), then the proportion of sets in that belong to is at most ; second, every element of belongs to the same number of sets
of subsets of with the following three properties. First, if is any element of (note that we have three levels of sets here, so an element of is a subset of and therefore a collection of subsets of ), then the proportion of sets in that belong to is at most ; second, every element of belongs to the same number of sets 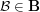 ; and third, every element of contains the same number of sets. If we can do that, then we can use the above results, but the nicest way to finish the argument is to reason probabilistically as follows. Let
; and third, every element of contains the same number of sets. If we can do that, then we can use the above results, but the nicest way to finish the argument is to reason probabilistically as follows. Let 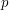 be the proportion of elements of that belong to . Then if we pick a random element of , it has a probability of belonging to . But another way of choosing a random element of is to choose a random element of and then a random set
be the proportion of elements of that belong to . Then if we pick a random element of , it has a probability of belonging to . But another way of choosing a random element of is to choose a random element of and then a random set 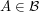 . This gives the uniform distribution on , since every element of has an equal probability of belonging to the randomly chosen set , and it then has a probability
. This gives the uniform distribution on , since every element of has an equal probability of belonging to the randomly chosen set , and it then has a probability 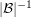 of being chosen from , and all the sets have the same size. But if no set in has a proportion greater than of elements that belong to , then the probability of choosing an element of by the second method is at most (since this is true whatever set you begin by choosing). It follows that
of being chosen from , and all the sets have the same size. But if no set in has a proportion greater than of elements that belong to , then the probability of choosing an element of by the second method is at most (since this is true whatever set you begin by choosing). It follows that 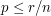 , which is what we wanted to prove.
, which is what we wanted to prove.
It remains to choose . Here we use another trick: exploiting symmetry. Suppose we can find just a single set with the property that no intersecting set-system ![\mathcal{A}\subset [n]^{(r)}](../images/tex/f7e0fcdf1a33bba0b23d998cb665cf83.png) can contain more than
can contain more than 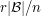 elements. Then the same will be true if we permute the set and take the corresponding transformation of . (To be precise, if
elements. Then the same will be true if we permute the set and take the corresponding transformation of . (To be precise, if  is a permutation of we would take the collection of all sets
is a permutation of we would take the collection of all sets 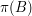 such that .) If we define to be the set of all such transformations of , then the symmetry of the situation means that every element of is contained in the same number of sets in . Thus, the problem is solved if we can find just one set
such that .) If we define to be the set of all such transformations of , then the symmetry of the situation means that every element of is contained in the same number of sets in . Thus, the problem is solved if we can find just one set ![\mathcal{B}\subset [n]^{(r)}](../images/tex/f2210541eeefa00fa8da26861e7cc477.png) that cannot contain a proportion greater than of sets that all intersect.
that cannot contain a proportion greater than of sets that all intersect.
We are closing in on our target. How can a proportion of arise? If is a multiple of , then it is quite easy to see how to do it. For instance, if 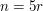 then we could take five disjoint sets of size , and obviously at most one of these sets can belong to an intersecting system. But if is coprime to , as it may well be, then we will need the number of sets in to be a multiple of . Are there any natural examples of subsets of that have a number of elements that is a multiple of ?
then we could take five disjoint sets of size , and obviously at most one of these sets can belong to an intersecting system. But if is coprime to , as it may well be, then we will need the number of sets in to be a multiple of . Are there any natural examples of subsets of that have a number of elements that is a multiple of ?
It's not quite clear what "natural' means here, so let's jump straight to the answer and then see if we can justify it somehow. The answer is to think of the set as the group of integers mod and to take all sets of the form 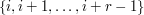 , where this is interpreted mod .
, where this is interpreted mod .
To see that this works, let us suppose we have an intersecting family of these sets. Without loss of generality one of the sets in the family is 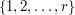 . Then all other sets in the family must be intervals that begin or end at one of the numbers from to . Let us write
. Then all other sets in the family must be intervals that begin or end at one of the numbers from to . Let us write 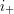 for the interval of length that begins at
for the interval of length that begins at 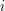 and
and 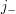 for the interval of length that ends at
for the interval of length that ends at 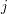 . Then if belongs to the family, we know that
. Then if belongs to the family, we know that 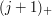 does not. Thus, we can have at most one out of each pair
does not. Thus, we can have at most one out of each pair 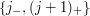 . There are
. There are 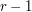 such pairs and every interval of length that intersects is contained in one of them, apart from the interval itself. Therefore, the family can have size at most , and the proof is complete.
such pairs and every interval of length that intersects is contained in one of them, apart from the interval itself. Therefore, the family can have size at most , and the proof is complete.
Why was the idea of choosing a cyclic collection of intervals a natural one? One answer is that it is a fairly natural generalization of the partitioning that worked when was a multiple of . Another is that if we are trying to find a nice subset of then one potential source of examples is orbits of group actions. If we want our subset to have size , then an obvious group to try is the cyclic group of order , since we can easily define an action by cyclically permuting the ground set. And finally, if we are arranging the elements of in a cycle, then the most natural set of size to consider is an interval. So even if it isn't instantly obvious that this example is going to work, it is one of the first examples one is likely to try.
In case that long discussion leaves the impression that the proof is rather long, here is the proof minus the accompanying justification. Let be an intersecting family. Let be the family of intervals of length mod . Let be a random permutation and let 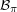 be the set of all such that . Then the size of
be the set of all such that . Then the size of 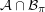 cannot be more than , by symmetry combined with the argument above that proves it when is the identity. On the other hand, the expected size of is
cannot be more than , by symmetry combined with the argument above that proves it when is the identity. On the other hand, the expected size of is 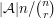 . It follows that
. It follows that 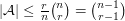 .
.
This theorem is called the Erdős-Ko-Rado theorem, and the proof by double counting is due to Gyula Katona.
Example 5: an identity concerning Euler's totient function
Euler's totient function 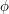 is the function that takes a positive integer to the number of positive integers less than and coprime to . For example, the integers less than
is the function that takes a positive integer to the number of positive integers less than and coprime to . For example, the integers less than 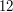 and coprime to are
and coprime to are 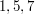 and
and 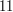 , so
, so 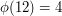 .
.
An important identity in elementary number theory is that 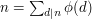 , where "
, where "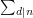 " means that we are summing over all factors of . For example, the factors of
" means that we are summing over all factors of . For example, the factors of 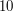 are
are 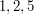 and , and
and , and 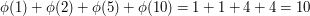 .
.
To prove this identity, we shall count the set in two different ways. The first way is the utterly obvious way: it has size by definition of "has size ". The definition being used here is that a set has size if and only if there is a one-to-one correspondence between and the set , which there obviously is if actually equals .
For the second way, we shall partition the set into subsets and add up the sizes of those subsets. To do this, we would like to define a subset for each factor of . Is there a natural way of doing this that will give rise to disjoint sets?
The answer to any question like this will be yes if we can find a function from to the set of all factors of . Then for each we take the set of all elements that map to . So is there a natural function of this kind?
Yes, and it's not hard to think of because there aren't any obvious alternatives: we define  to be
to be  , the highest common factor of and . This certainly maps to a factor of , and it also depends on in a natural way. So let's see if it works.
, the highest common factor of and . This certainly maps to a factor of , and it also depends on in a natural way. So let's see if it works.
Given a factor of , which integers map to ? That is, which integers have the property that 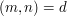 ? Well, they obviously have to be multiples of . But they also mustn't be multiples of any larger factor of . Since
? Well, they obviously have to be multiples of . But they also mustn't be multiples of any larger factor of . Since 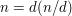 , a multiple
, a multiple 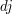 will have the property
will have the property 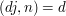 if and only if
if and only if 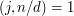 , that is, if and only if has no factors in common with
, that is, if and only if has no factors in common with 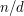 . Therefore, the number of such that
. Therefore, the number of such that 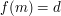 is equal to
is equal to 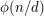 .
.
We have now shown that 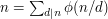 , which is not quite what we were trying to show. However, the map
, which is not quite what we were trying to show. However, the map 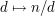 is a bijection from the set of factors of to itself, so it is in fact equivalent to what we wanted to show. (Another way of arguing would be to replace the map
is a bijection from the set of factors of to itself, so it is in fact equivalent to what we wanted to show. (Another way of arguing would be to replace the map 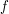 by the map
by the map 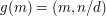 . Then the inverse image of would have size
. Then the inverse image of would have size 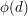 .)
.)
Example 6: evaluating zeta(2)
Euler's famous theorem that 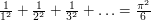 can also be proved by calculating the same quantity in two different ways. In this case the problem is no longer combinatorial, so the phrase "double count" is less appropriate, but the general philosophy is the same. This example requires some Fourier analysis.
can also be proved by calculating the same quantity in two different ways. In this case the problem is no longer combinatorial, so the phrase "double count" is less appropriate, but the general philosophy is the same. This example requires some Fourier analysis.
The quantity we shall calculate is the square of the 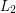 -norm of the function defined on the interval
-norm of the function defined on the interval ![[-\pi,\pi]](../images/tex/a5d4b5c6dcadd17bce3289ba1891d927.png) by taking
by taking 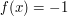 if
if 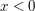 and
and 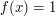 if
if 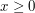 . Here we shall define the square of the -norm to be
. Here we shall define the square of the -norm to be 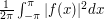 . The calculation is extremely easy, since
. The calculation is extremely easy, since 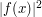 is identically 1, so we obtain the answer 1.
is identically 1, so we obtain the answer 1.
So far, this is not very interesting, but it becomes interesting if we exploit Parseval's identity, which tells us that the -norm of a function is equal to the 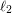 -norm of its sequence of Fourier coefficients. Thus, a second way of calculating the square of the -norm of is to work out its Fourier coefficients and add up the squares of their absolute values. Therefore, must be equal to
-norm of its sequence of Fourier coefficients. Thus, a second way of calculating the square of the -norm of is to work out its Fourier coefficients and add up the squares of their absolute values. Therefore, must be equal to 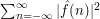 , where
, where 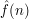 is defined to be
is defined to be 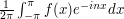 .
.
Now ![\int_0^\pi e^{-inx}dx=-\frac 1{in}[e^{-inx}]_0^\pi=-(e^{-in\pi}-1)/in](../images/tex/5c125e15d6381e93fc70655f093af4d5.png) . If is even, then
. If is even, then 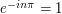 , so we get 0. If is odd, then
, so we get 0. If is odd, then 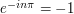 , and then we get
, and then we get 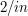 . After a very similar calculation for the part of the integral between
. After a very similar calculation for the part of the integral between 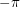 and
and 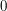 , and after taking account of the factor
, and after taking account of the factor 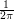 we find that
we find that 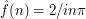 if is odd and if is even. It follows that the sum of the absolute values of the Fourier coefficients is
if is odd and if is even. It follows that the sum of the absolute values of the Fourier coefficients is 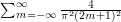 . Since the square of an odd number is equal to the square of minus that odd number, we can write this as
. Since the square of an odd number is equal to the square of minus that odd number, we can write this as 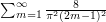 . Therefore,
. Therefore, 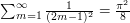 .
.
This is already a pretty interesting identity. To obtain Euler's theorem, we just note that the left-hand side is equal to 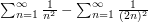 , which is three quarters of
, which is three quarters of 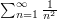 . So
. So  , which equals
, which equals 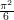 .
.
Another point of view
Giving a bipartite graph with vertex sets and is the same as giving
a relation 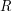 between and : we declare and
between and : we declare and 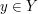 to
be related if there is an edge joining and . Equivalently,
if we identify the relation with its graph (i.e. if we think of
as being the subset of
to
be related if there is an edge joining and . Equivalently,
if we identify the relation with its graph (i.e. if we think of
as being the subset of 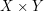 consisting of those ordered pairs
consisting of those ordered pairs
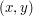 whose elements are related by ), then is precisely
the set of edges in the bipartite graph.
whose elements are related by ), then is precisely
the set of edges in the bipartite graph.
Now there are natural maps 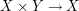 and
and
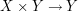 , given by projecting onto the first and second
factor respectively. Restricting these maps to , we obtain projections
, given by projecting onto the first and second
factor respectively. Restricting these maps to , we obtain projections
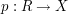 and
and 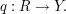
If 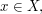 then the degree of (in the bipartite graph view-point) is just the order of the preimage
then the degree of (in the bipartite graph view-point) is just the order of the preimage
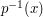 , and similarly the degree of is simply the order of
, and similarly the degree of is simply the order of
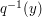 .
The sum over
.
The sum over 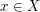 of the orders of all the preimages
is just the order of , as is the sum of the orders of all the preimages
, as ranges over the points of . Thus we get the
basic equality
of the orders of all the preimages
is just the order of , as is the sum of the orders of all the preimages
, as ranges over the points of . Thus we get the
basic equality
![\sum_{x \in X} | p^{-1}(x) | = \sum_{y \in Y} |q^{-1}(y) ].](../images/tex/116722d48d9f11494bee3de3068a5231.png)
(Both sides are equal to 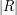 .)
This gives another
point of view on the basic principle of double counting discussed above.
.)
This gives another
point of view on the basic principle of double counting discussed above.
This point of view, using the graph of the relation and the maps
and 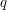 , can be applied to extend the idea of double counting to
other contexts. For example, in algebraic geometry it gives rise
to the technique of dimension counting via incidence varieties.
, can be applied to extend the idea of double counting to
other contexts. For example, in algebraic geometry it gives rise
to the technique of dimension counting via incidence varieties.
Example 7: fixed points and orbits of group actions
Here is an example from the theory of group actions.
Suppose that the finite group acts on the finite set .
There is a rather natural relation to consider on 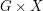 ,
related to the study of fixed points for the action. Namely,
we define
,
related to the study of fixed points for the action. Namely,
we define 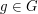 and to be related if
and to be related if 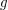 fixes .
More symbolically, we define a relation via
fixes .
More symbolically, we define a relation via
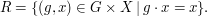
Now as above we have the projections
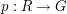 and
and 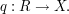 Let us see what we can deduce from the double counting formula
applied in this context.
Let us see what we can deduce from the double counting formula
applied in this context.
We begin by interpreting 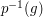 , for . This is just
the set of fixed points of acting on , which we denote by
, for . This is just
the set of fixed points of acting on , which we denote by 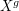 .
.
What about 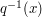 , for ? This is precisely the stabilizer
of , i.e. the subgroup of consisting of points which fix ,
which we denote by
, for ? This is precisely the stabilizer
of , i.e. the subgroup of consisting of points which fix ,
which we denote by 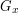 .
.
Thus double counting gives the identity
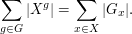
We can reinterpret this formula by recalling that
if and lie in the same orbit of ,
then and 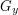 are conjugate. Indeed, if
are conjugate. Indeed, if 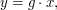 then a simple calculation shows that
then a simple calculation shows that 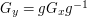 .
Thus we can regroup the second sum into a sum over
a set of orbit class representatives
.
Thus we can regroup the second sum into a sum over
a set of orbit class representatives 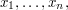 and so rewrite it as
and so rewrite it as
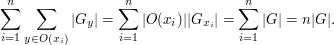
(Here 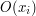 denotes the orbit of
denotes the orbit of 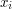 , and we have used the formula
, and we have used the formula
![G_{x_i}].](../images/tex/b3d6b38077b838c9af2461806384a967.png) )
Altogether, we conclude that
)
Altogether, we conclude that
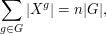
where denotes the number of orbits of acting on .
Dividing both sides by 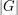 , we find that
, we find that
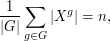
or, in words:
The average number of fixed points of an element of acting on
is equal to the number of orbits of acting on .
This useful relation between fixed points and orbits is known as Burnside's lemma.
Comments
Post new comment
(Note: commenting is not possible on this snapshot.)