- Quick description
- Contents
- Example 1: measure theory is not trivial
- Example 2: the fundamental theorem of arithmetic is not trivial
- Example 3: the Archimedean property is not trivial
- General discussion
- Example 4: Cauchy-Schwarz arguments are not enough for Roth's theorem
- Example 5: a precise reason that the P versus NP problem is hard
- Example 6: a precise reason that the prime number theorem is hard
- Example 7: finding a dilate with gaps
- General discussion
- Example 8: a conjecture of Erdős
Quick description
Sometimes one gets stuck simply because one has run out of ideas. But sometimes it is for a different reason: one has ideas, but one gets bogged down in technical details and cannot get them to work, or cannot face trying. Or perhaps a result seems obvious, but you just can't quite find a rigorous proof. If that happens to you, it can be very helpful to try to formulate precisely what your approach actually is. Sometimes you will then find that you can make it work, and sometimes you will manage to prove rigorously that it cannot work. In the latter case, you will usually have important information about what a correct proof would have to look like.
Contents
Example 1: measure theory is not trivial
Example 2: the fundamental theorem of arithmetic is not trivial
Example 3: the Archimedean property is not trivial
Example 4: Cauchy-Schwarz arguments are not enough for Roth's theorem
Example 5: a precise reason that the P versus NP problem is hard
Example 6: a precise reason that the prime number theorem is hard
Example 7: finding a dilate with gaps
Example 8: a conjecture of Erdős
Example 1: measure theory is not trivial
Let 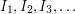 be half-open intervals in the real line, with the length of
be half-open intervals in the real line, with the length of 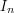 equal to
equal to 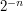 . In other words, is an interval of the form
. In other words, is an interval of the form 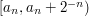 . Can the union of these intervals contain every real number in the interval
. Can the union of these intervals contain every real number in the interval 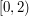 ?
?
At first sight, the answer seems obvious: the lengths of the intervals add up to 1 (since they are 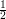 ,
, 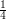 ,
, 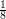 , and so on). Since the interval from 0 to 2 has length 2, we don't have enough length to cover this interval.
, and so on). Since the interval from 0 to 2 has length 2, we don't have enough length to cover this interval.
Since that reasoning sounds quite convincing, let us try to turn it into a rigorous proof. It might go something like this. Let us imagine that we place the intervals down one by one, possibly overlapping, on to the real line. When we put down the first one, then four things can happen: we may miss the interval altogether, we may overlap it and contain some numbers larger than 2, we may overlap it and contain some numbers less than 0, or our interval may be contained in . In the first case, what is left uncovered is all of ; in the second it is an interval of the form 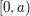 with
with 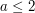 ; in the third it is an interval of the form
; in the third it is an interval of the form 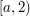 with
with 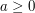 ; and in the fourth it is a set of the form
; and in the fourth it is a set of the form 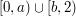 with
with 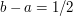 . In all four cases the uncovered points form a union of at most two intervals, with total length at least 3/2.
. In all four cases the uncovered points form a union of at most two intervals, with total length at least 3/2.
Continuing in this vein, we can prove quite easily (and rigorously) that after we have placed the intervals 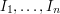 ,
we are left with a finite union of disjoint intervals of total length at least
,
we are left with a finite union of disjoint intervals of total length at least 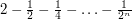 . If we write
. If we write 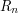 for this union (the letter R standing for "residue") then we find that
for this union (the letter R standing for "residue") then we find that 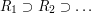 and that every is a finite union of disjoint intervals with total length greater than 1.
and that every is a finite union of disjoint intervals with total length greater than 1.
Surely in that case it follows that the intersection of the sets has total length at least 1. Why can't we just say that and have done with it? The problem is that we have to say what we mean by "length", and while that is easy enough for finite unions of disjoint intervals (just add up the lengths of the intervals, where the length of the interval 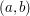 is defined to be
is defined to be 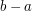 , and similarly for closed and half-open intervals), it is not quite so obviously easy for intersections of infinitely many such unions, even if they are nested. For example, the Cantor set is a pretty complicated set, but there is no difficulty in representing it as the intersection of a nested sequence of finite unions of intervals.
, and similarly for closed and half-open intervals), it is not quite so obviously easy for intersections of infinitely many such unions, even if they are nested. For example, the Cantor set is a pretty complicated set, but there is no difficulty in representing it as the intersection of a nested sequence of finite unions of intervals.
Perhaps we could define the length of such a set to be the limit of the (decreasing sequence of the) lengths of the finite unions of disjoint intervals. Doesn't that solve the problem in a nice simple way? Unfortunately not, because if we do that then we must prove that this definition is consistent. That is, we must prove that if we represent the same set in two different ways as a nested intersection of finite unions of disjoint intervals, as we undoubtedly can, then we will arrive at the same answer for the length. This is directly important to us, since otherwise it is conceivable that we could assign a length of 1 to the empty set, and if we could do that then we could not say with any confidence that the intersection of the sets is non-empty, which is what we are trying to prove.
Here is another possible argument. Let us place the intervals down in such a way that each one covers as much of as possible. Clearly, the best way to do this is to make them disjoint. For example, we could set 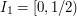 ,
, 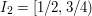 ,
, 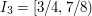 , and so on. But then the union of all the is
, and so on. But then the union of all the is 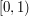 . Since this union was clearly as big as it could possibly be, it is impossible to cover all of .
. Since this union was clearly as big as it could possibly be, it is impossible to cover all of .
What is wrong with this argument? The answer is more or less the same as before. What was meant by "as much ... as possible"? That suggests some notion of size for subsets of , and for the argument to work, that notion of size must apply to the union of the intervals , and once again we find ourselves needing to prove that such an assignment can be done in a consistent way.
Now this can be done: the appropriate notion is called Lebesgue measure. However, it is not at all straightforward to set up Lebesgue measure, and if you try to do it you will find that at some point you need to convince yourself of a fact that is very similar to the fact that we are trying to prove. So even this answer is somewhat question-begging.♦
It is at this point that we should try to follow the advice in the title of this article: we shall see if we can prove in a rigorous way that our approaches so far cannot establish the statement that we are trying to prove. But to do this we need to be very clear about what our approaches are. Here is an attempt to do this.
-
First approach: if
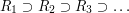 are finite unions of disjoint intervals, and the total length of the intervals that make up is always at least 1, then the intersection of all the clearly cannot be empty.
are finite unions of disjoint intervals, and the total length of the intervals that make up is always at least 1, then the intersection of all the clearly cannot be empty. -
Second approach: if a disjoint collection of intervals does not cover
, then you obviously cannot make it cover by translating the intervals.
As ever, if you want to find the weak point in an argument, look out for words and phrases such as "clearly", "obviously", or "it is easy to see that". Often they indicate the place that the writer is not quite 100% sure about.
Let's focus on the second argument for a while, and try to see why it seems plausible. One possible reason is this. Imagine that you arranged your intervals to be 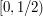 ,
, 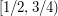 ,
, 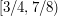 , and so on. Now imagine that we translate these intervals one by one to their new places. Then at each stage there is no hope of covering , so we don't cover by the end of the process.
, and so on. Now imagine that we translate these intervals one by one to their new places. Then at each stage there is no hope of covering , so we don't cover by the end of the process.
If we examine that last sentence carefully, we see that the first assertion can be justified (because at each stage we have a disjoint finite union of intervals of total length at most 1) but the "so" part involves something more. In general it's absolutely not permitted to say that if something happens at every finite stage of an infinite process then it happens for the whole process. To give an immediate example, we have a finite union of disjoint intervals at every finite stage of our process, but we do not necessarily have a finite union of disjoint intervals at the end of the process.
We seem to keep running into similar problems. But what does it mean to prove rigorously that our approach cannot work? It can in fact mean various different things, but one way of demonstrating convincingly that an approach cannot work is to show that the same approach in a different context gives rise to a false result. So let's see if we can think of a different context. We'll need a context in which we can make sense of the notion of an interval, or at least of a type of set where we can say how large it is, and where the largeness doesn't change when we translate a set. And we'll want it to be the case that the class of disjoint finite unions of sets of the given type is closed under finite unions and intersections. And we'll want the sizes of all these sets to be well-defined. And so on.
The easiest example in this case is obtained by looking at intervals of rational numbers rather than intervals of real numbers. How does one come up with this example? Just by looking at the given example and seeing whether anything in it could be generalized. One candidate is "real number", which one might consider generalizing to "element of some number system". But for intervals to be sensible objects, we need the number system to be one-dimensional and "dense", so the rational numbers are the obvious example (even if one could imagine other examples such as 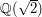 ).
).
And sure enough, the result is false for rational numbers. To see why, just enumerate all the rationals in and make sure that the  th rational is contained in .
th rational is contained in .
What this example demonstrates is that any proof must use some feature of the reals that is not true of the rationals. And it's not hard to guess what this feature will be: the completeness property. This gives us a big clue about what a correct proof will have to look like. Almost certainly it will prove that the intervals don't cover not by directly coming up with a number that is not covered, but by coming up with a sequence of numbers such that the limit is not covered. And once we've had that thought, we should recognise that we are probably looking for a just-do-it proof.
Let's go back then to our sequence of sets 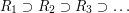 , each of which was a finite union of disjoint intervals of total length at least 1. We'd like to find a point that belongs to every single . A natural way to try to do this would be to build a sequence of nested closed intervals
, each of which was a finite union of disjoint intervals of total length at least 1. We'd like to find a point that belongs to every single . A natural way to try to do this would be to build a sequence of nested closed intervals 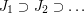 with
with 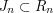 ,
but this doesn't work because there is no reason for
,
but this doesn't work because there is no reason for 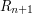 to intersect
to intersect 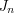 . But we can use the more general fact that a nested sequence of closed bounded sets has a nonempty intersection. Then our task is to find subsets
. But we can use the more general fact that a nested sequence of closed bounded sets has a nonempty intersection. Then our task is to find subsets 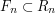 with
with 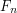 closed. Recall that what we know about is that it is a finite union of disjoint intervals.
closed. Recall that what we know about is that it is a finite union of disjoint intervals.
The obvious way of finding a closed subset of , given that it suits us to have as big as possible, is to take the intervals that make up and make them closed, and, if necessary, very slightly smaller. For instance, if one of the intervals is 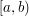 then we'll change it to
then we'll change it to ![[a,b-\epsilon]](../images/tex/1ed7d3a31af45db3cd7604882024346d.png) for some very small
for some very small  . But that doesn't quite work because we want the sets to be nested too. Just to express more easily what we shall do about this, let us write
. But that doesn't quite work because we want the sets to be nested too. Just to express more easily what we shall do about this, let us write 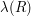 for the total length of the intervals that make a finite union
for the total length of the intervals that make a finite union 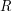 of disjoint intervals.
of disjoint intervals.
We now define 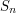 to be a finite union of disjoint closed intervals such that
to be a finite union of disjoint closed intervals such that 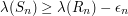 . Then we define to be the intersection of the sets
. Then we define to be the intersection of the sets 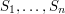 . This will be with some intervals removed, the total length of which is at most
. This will be with some intervals removed, the total length of which is at most 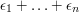 . So if we choose the
. So if we choose the 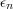 to sum to
to sum to 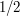 , say, then
, say, then 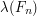 is always at least , which implies that is nonempty. And now we are done.
is always at least , which implies that is nonempty. And now we are done.
For the purposes of this article, the main point of interest in the above proof is that it used the fact that the intersection of a nested sequence of closed bounded sets is nonempty, which is a theorem that's very much about the real numbers. (It follows easily from the Bolzano-Weierstrass theorem.) And we were led to it by realizing that we had to use such a theorem because the result was false for the rationals.
Example 2: the fundamental theorem of arithmetic is not trivial
Having given one example at great length, let us now be a bit briefer. Another result that is often thought, wrongly, to be obvious is the fundamental theorem of arithmetic: that every positive integer has a unique factorization into primes. Or if the theorem itself doesn't seem completely obvious, special cases of it do, such as that if 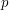 ,
, 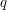 ,
,  and
and  are distinct primes then
are distinct primes then 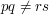 . Here again, there is a context in which the result is false: in the ring
. Here again, there is a context in which the result is false: in the ring 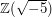 of numbers of the form
of numbers of the form 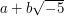 , where
, where  and
and 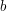 are integers, the number
are integers, the number 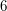 can be factorized either as
can be factorized either as 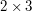 or as
or as 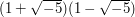 , and the numbers
, and the numbers 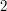 ,
, 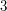 ,
, 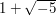 and
and 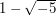 cannot be factorized any further.♦ Therefore, any proof of the fundamental theorem of arithmetic must use some aspect of the integers that is not true of . This property turns out to be the Euclidean property, which says that for any two numbers and
cannot be factorized any further.♦ Therefore, any proof of the fundamental theorem of arithmetic must use some aspect of the integers that is not true of . This property turns out to be the Euclidean property, which says that for any two numbers and 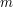 we can write
we can write 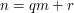 with smaller than .
with smaller than .
Example 3: the Archimedean property is not trivial
Another statement that seems more obvious than it actually is is the Archimedean property of the real numbers: that if  is a non-negative real number that is less than
is a non-negative real number that is less than 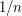 for every positive integer , then must be
for every positive integer , then must be 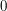 .
.
In one sense this is obvious. If you think of a real number as something with an infinite decimal expansion, then the fact that is less than 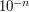 implies that is less than
implies that is less than 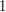 and the first digits after the decimal point are . And that forces to be
and the first digits after the decimal point are . And that forces to be 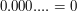 .
.
However, if you are developing the theory of the reals axiomatically (as the unique complete ordered field), then the statement that every real number has a decimal expansion becomes something that needs to be proved, and the proof uses the Archimedean property. So is the Archimedean property obvious in this more abstract setting?
This time the result is certainly true of the rationals, and easy to prove: every positive rational number is of the form 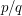 and is not less than
and is not less than 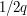 . This perhaps also contributes to the feeling of obviousness of the Archimedean property. But it is not in fact a good example to look at: if you look at a smaller number system, then the result is more likely to be true, since there are fewer numbers that could be counterexamples. However, it does focus our minds on a useful question. Both the rationals and the reals are ordered fields. Is the result true for every ordered field?
. This perhaps also contributes to the feeling of obviousness of the Archimedean property. But it is not in fact a good example to look at: if you look at a smaller number system, then the result is more likely to be true, since there are fewer numbers that could be counterexamples. However, it does focus our minds on a useful question. Both the rationals and the reals are ordered fields. Is the result true for every ordered field?
To answer this question one can try to construct an ordered field for which the result is false. Since any ordered field that contains another ordered field that fails the Archimedean property must itself fail the Archimedean property, it makes sense to look for an example that is in some sense minimal. This means that a good method to use is finding a universal construction. For convenience we give the construction here, but it is discussed from a slightly different perspective in the article just mentioned (as Example 2). We shall take an ordered field such as 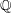 or
or 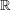 and simply adjoin an element that is positive and smaller than every . To simplify the discussion we'll go for . Since the Archimedean property holds for (even if we haven't yet proved it), will in fact be smaller than every positive real number. From this a number of consequences follow. For instance, since we are trying to produce a field,
and simply adjoin an element that is positive and smaller than every . To simplify the discussion we'll go for . Since the Archimedean property holds for (even if we haven't yet proved it), will in fact be smaller than every positive real number. From this a number of consequences follow. For instance, since we are trying to produce a field, 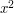 must also be an element, and it will be smaller than . And
must also be an element, and it will be smaller than . And 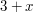 will be smaller than any real number that is greater than . If one explores these consequences, one finds that the elements that are forced to belong to the field are all elements of the form
will be smaller than any real number that is greater than . If one explores these consequences, one finds that the elements that are forced to belong to the field are all elements of the form 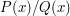 where
where 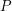 and
and 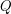 are polynomials and is not the zero polynomial. And of course if
are polynomials and is not the zero polynomial. And of course if 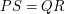 then and
then and 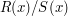 are the same element. As for the ordering, we can work it out as follows. We say that
are the same element. As for the ordering, we can work it out as follows. We say that 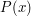 is positive if the leading coefficient of is positive, and otherwise it is negative. And is positive if and have the same sign. And finally, is less than if
is positive if the leading coefficient of is positive, and otherwise it is negative. And is positive if and have the same sign. And finally, is less than if 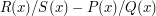 is positive. It is not too hard to check that this is a well-defined ordering that gives us an ordered field (and that the entire ordering is determined by the one fact that is smaller than any constant polynomial). So now we have our ordered field in which the Archimedean property is false.
is positive. It is not too hard to check that this is a well-defined ordering that gives us an ordered field (and that the entire ordering is determined by the one fact that is smaller than any constant polynomial). So now we have our ordered field in which the Archimedean property is false.
What we learn from this example is that we have to use the completeness property of the reals if we want to prove the Archimedean property. Once we have realized this, the proof is easy: the sequence 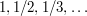 is decreasing and bounded below, so it has a greatest lower bound . If
is decreasing and bounded below, so it has a greatest lower bound . If 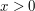 , then there must be some such that
, then there must be some such that 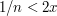 , by the definition of a greatest lower bound. But then
, by the definition of a greatest lower bound. But then 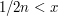 , which is a contradiction. Therefore, since is a lower bound, is the greatest lower bound. But that is precisely the statement that for every there exists such that
, which is a contradiction. Therefore, since is a lower bound, is the greatest lower bound. But that is precisely the statement that for every there exists such that 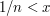 .
.
General discussion
Examples 1-3 all have a similar form: a statement seems obvious, and in order to understand why it is not obvious one finds a similar context in which it is false. However, that is by no means the only way that the principle under discussion can be used. Here are some examples of different kinds.
Example 4: Cauchy-Schwarz arguments are not enough for Roth's theorem
Let 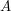 be a subset of a finite Abelian group
be a subset of a finite Abelian group 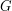 . Suppose that has elements and has
. Suppose that has elements and has 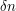 elements. What is the minimum possible number of quadruples
elements. What is the minimum possible number of quadruples 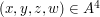 such that
such that 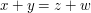 ?
?
A rather simple argument solves this problem pretty satisfactorily. Let 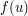 be the number of ways of writing
be the number of ways of writing 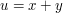 with and
with and 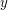 in . Then
in . Then 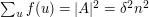 , since every pair
, since every pair 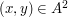 contributes 1 to the value of
contributes 1 to the value of 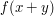 and hence 1 to the sum. Also,
and hence 1 to the sum. Also, 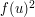 is the number of quadruples such that
is the number of quadruples such that 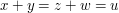 , so
, so 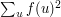 is equal to the number of quadruples such that . But a simple application of the Cauchy-Schwarz inequality proves that
is equal to the number of quadruples such that . But a simple application of the Cauchy-Schwarz inequality proves that 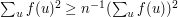 . (Actually, the best way of seeing this is to observe that
. (Actually, the best way of seeing this is to observe that 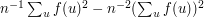 is the variance of
is the variance of 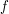 and is therefore non-negative.)◊ This proves that one cannot have fewer than
and is therefore non-negative.)◊ This proves that one cannot have fewer than 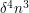 quadruples in with .
quadruples in with .
A random subset of will typically have about such quadruples, so this argument gives a result that is close to best possible. However, let us focus on the fact that we have managed to use the Cauchy-Schwarz inequality to obtain a good lower bound.
Now let us vary the problem and ask how many arithmetic progressions of length 3 can contain. Let us assume that our group has odd order, so that any two elements have a unique average. Now we are trying to evaluate a different quantity, but in some ways it is quite similar. For instance, if we define as above, and define 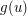 to be 1 if
to be 1 if 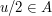 and otherwise, then what we are counting is
and otherwise, then what we are counting is 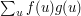 (at least if we allow degenerate progressions where all three terms are the same, so let's say that we do allow these). The functions and
(at least if we allow degenerate progressions where all three terms are the same, so let's say that we do allow these). The functions and 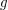 are closely connected, so can we manipulate this sum in some way and end up with a quantity that is at least
are closely connected, so can we manipulate this sum in some way and end up with a quantity that is at least 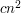 for some constant
for some constant  that depends on
that depends on 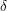 but not on ?
but not on ?
It doesn't seem to be easy, so let us try to prove rigorously that we can't find a proof that resembles the proof that worked so well for quadruples. This time we won't vary the context, but we'll see whether the proof for quadruples yields anything stronger and has the property that the corresponding strengthening for progressions is false.
One natural way of generalizing any problem in this area is to turn sets into functions. If you try this for the quadruples problem, you quickly find that precisely the same proof establishes the following result. If is any real-valued function defined on , then 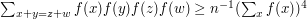 . In particular, the result remains true even when is allowed to take negative values, provided only that the average is positive.
. In particular, the result remains true even when is allowed to take negative values, provided only that the average is positive.
Now let us ask whether the same can be said for progressions of length 3. This question is easy to answer. Rather than specify a counterexample, let us see how one can be constructed. You just choose a fairly arbitrary function of average 0. Unless you are very unlucky, the sum 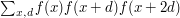 will not be 0. If it is negative, then you have a counterexample. If it is positive, then replace by
will not be 0. If it is negative, then you have a counterexample. If it is positive, then replace by 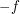 and you have a counterexample. And if you want the average to be positive and to be negative, then make a small perturbation to an example where the average is zero and the sum negative.
and you have a counterexample. And if you want the average to be positive and to be negative, then make a small perturbation to an example where the average is zero and the sum negative.
What this demonstrates fairly convincingly (though perhaps not quite 100 percent rigorously) is that if you want a lower bound of the form 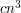 for the number of progressions of length 3 in , then the fact that you are looking at a non-negative function (the characteristic function of ) is going to be important in a way that it isn't for the quadruples problem. And indeed this turns out to be the case. It also goes a long way towards explaining why the progressions problem is a difficult one: one of the best tools for problems about configurations of integers is discrete Fourier analysis, but the notion of positivity is hard to translate into a property about the Fourier transform.
for the number of progressions of length 3 in , then the fact that you are looking at a non-negative function (the characteristic function of ) is going to be important in a way that it isn't for the quadruples problem. And indeed this turns out to be the case. It also goes a long way towards explaining why the progressions problem is a difficult one: one of the best tools for problems about configurations of integers is discrete Fourier analysis, but the notion of positivity is hard to translate into a property about the Fourier transform.
A different argument that suggests that using tools like the Cauchy-Schwarz inequality will not be sufficient is that there is a lower bound for the problem that exceeds any upper bound of the kind that the Cauchy-Schwarz inequality every produces. This fact is discussed in detail in the article on what a lower bound can say about the proof of the upper bound.
Example 5: a precise reason that the P versus NP problem is hard
There is a spectacular example, which cannot be explained in detail here, due to Alexander Razborov and Stephen Rudich. A problem on which the whole mathematical world is well and truly stuck is the P versus NP problem. Some wonderfully clever methods have been developed that solve problems that appear to be closely related – for example, proofs that certain functions cannot be computed in polynomial time if you make natural restrictions on the nature of the computation – but these methods all seem to break down when you try to apply them to the P versus NP problem itself. Razborov and Rudich had the idea of trying to understand as precisely as possible why this was the case.
The result was that they formulated a notion that they called a natural proof that P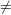 NP. This notion had three properties. First, it lived up to its name: it really did seem that any natural approach to the problem would give rise to a proof that was natural in their technical sense. Secondly, all known proofs of related results were natural in their sense. Thirdly, there was very strong evidence that there was no natural proof that PNP, because they were able to prove that if such a proof exists, then the discrete logarithm problem can be solved in polynomial time. (The discrete logarithm problem is this: given a generator of the multiplicative group mod and some element of this group, find such that
NP. This notion had three properties. First, it lived up to its name: it really did seem that any natural approach to the problem would give rise to a proof that was natural in their technical sense. Secondly, all known proofs of related results were natural in their sense. Thirdly, there was very strong evidence that there was no natural proof that PNP, because they were able to prove that if such a proof exists, then the discrete logarithm problem can be solved in polynomial time. (The discrete logarithm problem is this: given a generator of the multiplicative group mod and some element of this group, find such that 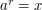 . If you can solve this you can factorize large integers, so it is a problem that is "known to be almost certainly hard".) This result has had a very important effect on research in theoretical computer science: now if you want to make an assault on the P versus NP problem, one of the first things you have to do is make sure your approach will not lead to a natural (or "naturalizable") proof, since if it does then you are doomed to failure.
. If you can solve this you can factorize large integers, so it is a problem that is "known to be almost certainly hard".) This result has had a very important effect on research in theoretical computer science: now if you want to make an assault on the P versus NP problem, one of the first things you have to do is make sure your approach will not lead to a natural (or "naturalizable") proof, since if it does then you are doomed to failure.
For more details about this, there is a Wikipedia article on natural proofs, and the introduction to the original paper of Razborov and Rudich is very readable.
Example 6: a precise reason that the prime number theorem is hard
The discussion of this example is a brief digest of a much longer and highly recommended blog post of Terence Tao about the parity problem in sieve theory.
One might think that a natural approach to proving the prime number theorem would be to argue as follows. It is difficult to estimate directly the number of primes in the interval 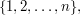 but we know that the set of primes is the complement of the union of the arithmetic progressions
but we know that the set of primes is the complement of the union of the arithmetic progressions 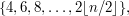
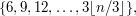 and so on. We can estimate the sizes of these arithmetic progressions very accurately – for example, the first has size within of
and so on. We can estimate the sizes of these arithmetic progressions very accurately – for example, the first has size within of 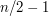 – and the intersection of any two of them is another set of a similar type, so the situation appears to be tailor-made for a use of the inclusion-exclusion principle.
– and the intersection of any two of them is another set of a similar type, so the situation appears to be tailor-made for a use of the inclusion-exclusion principle.
However, if one tries to develop a proof along these lines, then it seems to be very hard to avoid having so many terms that even the small errors associated with each term mount up and swamp the entire estimate. This is definitely the case if one just jumps in and applies the formula in the most obvious way, but there are plenty of non-obvious ways of applying the same basic idea, some of which have been used to prove some highly non-trivial results in analytic number theory, and none of them seems to be strong enough to yield the prime number theorem (let alone stronger statements such as the Riemann hypothesis).
A beautiful explanation for this was pointed out by Selberg. For each positive integer let 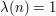 if has an even number of (not necessarily distinct) prime factors and let
if has an even number of (not necessarily distinct) prime factors and let 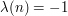 if has an odd number of prime factors. The function
if has an odd number of prime factors. The function 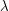 is typical of a function that is expected to "behave randomly", and indeed random-like behaviour can be proved if one assumes the generalized Riemann hypothesis. One manifestation of this random-like behaviour is that if you take a moderately long arithmetic progression and look at the sum
is typical of a function that is expected to "behave randomly", and indeed random-like behaviour can be proved if one assumes the generalized Riemann hypothesis. One manifestation of this random-like behaviour is that if you take a moderately long arithmetic progression and look at the sum 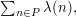 then the answer you get will be very small. In other words, each contains roughly the same number of s as
then the answer you get will be very small. In other words, each contains roughly the same number of s as 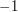 s.
s.
Now if we could find some clever modification of the inclusion-exclusion formula that led to an approximation of the primes by a set-theoretic combination of not too many arithmetic progressions 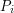 , each of which was fairly long, then each sum
, each of which was fairly long, then each sum 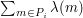 would be very small, which would lead us to the conclusion that
would be very small, which would lead us to the conclusion that 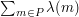 was small (where stands for the set of primes less than ), unless the error terms were big enough to swamp the (small) main term. But that conclusion is false, since
was small (where stands for the set of primes less than ), unless the error terms were big enough to swamp the (small) main term. But that conclusion is false, since 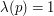 for every prime , and the accumulation of error terms is precisely the situation we were trying to avoid.
for every prime , and the accumulation of error terms is precisely the situation we were trying to avoid.
This is known as the parity problem in sieve theory: it tells us that no simple sieve-theoretic approach can yield the prime number theorem as a consequence. Although the parity problem is a negative result, it also gives us a significant insight into the problem, and helps us to focus on approaches to these problems that might have a chance of working. In that respect, it plays a similar role that the natural-proofs result plays for the P-versus-NP problem (discussed in the previous example).
Example 7: finding a dilate with gaps
The following is a very nice-looking problem in additive combinatorics. Let be a prime and write 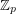 for
for 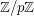 . Let be a subset of of size
. Let be a subset of of size 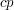 for some fixed positive constant . Now let us ask about the structure of the sets
for some fixed positive constant . Now let us ask about the structure of the sets 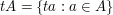 , which are the dilates of , focusing in particular on the question of whether we can find a
, which are the dilates of , focusing in particular on the question of whether we can find a 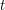 such that
such that 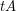 has no large gaps, where a gap of length simply means a set of the form
has no large gaps, where a gap of length simply means a set of the form 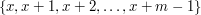 that contains no element of .
that contains no element of .
If is a random set, then we will expect there to be at least some gaps of size proportional to 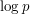 . The reason for this is that the probability that any fixed interval of length is a gap is
. The reason for this is that the probability that any fixed interval of length is a gap is 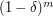 , and there are intervals, so the expected number of gaps of length in any given dilate of is
, and there are intervals, so the expected number of gaps of length in any given dilate of is 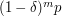 . If we choose so that
. If we choose so that 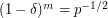 , say, then the expected number of gaps is
, say, then the expected number of gaps is 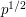 , and it can be shown that with very high probability we will have at least one gap. Since this is true for each , we find that if is a random set of size , then every dilate will have a gap of logarithmic size. (That was an easy application of the probabilistic method.)
, and it can be shown that with very high probability we will have at least one gap. Since this is true for each , we find that if is a random set of size , then every dilate will have a gap of logarithmic size. (That was an easy application of the probabilistic method.)
Having looked at the behaviour of random sets, let us go to the opposite extreme and think about highly structured sets. For example, what if we take to be the interval 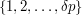 ? In that case, we can choose to be the integer
? In that case, we can choose to be the integer 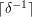 , and we obtain a dilate with no gap larger than , which is of constant size.
, and we obtain a dilate with no gap larger than , which is of constant size.
After a little more experiment of this kind, one is led to conjecture that for every set of size 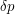 there is some such that the dilate has no gap of size greater than
there is some such that the dilate has no gap of size greater than 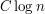 , where
, where 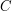 is a constant that depends on only.
is a constant that depends on only.
How might one go about proving this conjecture? One way might be to reformulate it as follows. Let 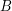 be the complement of . If no dilate has the desired property, then for every the dilate
be the complement of . If no dilate has the desired property, then for every the dilate 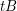 contains an interval
contains an interval 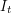 of length greater than
of length greater than 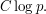 This means that contains an arithmetic progression
This means that contains an arithmetic progression 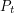 (mod ) of length greater than
(mod ) of length greater than 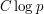 and with common difference
and with common difference 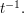 Since this is true for every , we are asking whether it is possible to find a union of
Since this is true for every , we are asking whether it is possible to find a union of 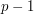 arithmetic progressions of length greater than , one for each possible common difference, with total size at most
arithmetic progressions of length greater than , one for each possible common difference, with total size at most 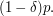 This sounds like quite an approachable problem: for instance, a first observation is that a typical pair of these progressions will have an intersection of size 1 (though this will not be the case for all pairs), which suggests that it will be hard to pack them all into a small set.
This sounds like quite an approachable problem: for instance, a first observation is that a typical pair of these progressions will have an intersection of size 1 (though this will not be the case for all pairs), which suggests that it will be hard to pack them all into a small set.
However, that observation on its own is nothing like enough: the same would be true of random subsets of size taken from a set of size 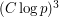 , say. So some more detailed structural property of the set system
, say. So some more detailed structural property of the set system 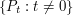 is needed. What might this property be?
is needed. What might this property be?
If you pursue this line of thought you will probably find that you eventually get stuck. And it turns out that there is an example that suggests very strongly that the problem is less combinatorial than it at first appears. Although we have not said so explicitly, in the back of our minds (if we are unfamiliar with the example to follow) is the thought that there are sets to choose from, and if some of them have large gaps then we can try to get rid of those gaps using a suitable dilation. Or perhaps even a random dilation will work.
However, is this unspoken assumption correct? Or might there be a set such that there are in fact very few distinct dilates ? As soon as one asks this question, one realizes (at least if one is familiar with the advice that one should not forget that the multiplicative group of 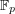 is cyclic) that the answer is yes. If is a generator (that is, if every non-zero integer mod is a power of ) and if
is cyclic) that the answer is yes. If is a generator (that is, if every non-zero integer mod is a power of ) and if 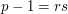 for some small , then we could take to be the set
for some small , then we could take to be the set 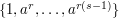 . Then each dilate has the form
. Then each dilate has the form 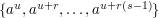 , so there are precisely distinct dilates. Another description of is that it is the set of all th powers. In particular, if
, so there are precisely distinct dilates. Another description of is that it is the set of all th powers. In particular, if 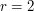 then is a set of size
then is a set of size 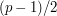 that consists of all quadratic residues, and the dilate is equal to if is a quadratic residue, and
that consists of all quadratic residues, and the dilate is equal to if is a quadratic residue, and 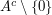 if is a quadratic nonresidue.
if is a quadratic nonresidue.
With this set , our question becomes the following: is it the case that neither the set of quadratic residues nor the set of quadratic nonresidues has a gap of size greater than ? That is, given an interval of length , must it contain at least one residue and at least one nonresidue?
This, it turns out, is very close to a famous question in number theory: how large an do you have to take before you are guaranteed that there will be a quadratic nonresidue mod amongst the numbers 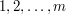 ? The answer should take the form of some function of , with again being the best one can reasonably hope for. It has not even been proved that there is a bound of the form
? The answer should take the form of some function of , with again being the best one can reasonably hope for. It has not even been proved that there is a bound of the form 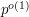 . That is, it has not been ruled out that there is some positive constant
. That is, it has not been ruled out that there is some positive constant  such that, for infinitely many , every number between and
such that, for infinitely many , every number between and 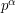 is a quadratic residue. Even with the help of the Generalized Riemann Hypothesis, the best known upper bound is
is a quadratic residue. Even with the help of the Generalized Riemann Hypothesis, the best known upper bound is 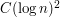 .
.
What bearing does this have on our original problem? Well, the problem is no easier to solve if we make the additional assumption that is a quadratic nonresidue (which is the case if and only if 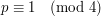 ), and if is a quadratic nonresidue then the numbers
), and if is a quadratic nonresidue then the numbers 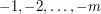 will all be nonresidues if the numbers are all residues. Therefore, if there exist primes for which are all residues for unexpectedly large can be found, then our original combinatorial conjecture is false.
will all be nonresidues if the numbers are all residues. Therefore, if there exist primes for which are all residues for unexpectedly large can be found, then our original combinatorial conjecture is false.
One possible reaction to this would be to say that we have found a combinatorial generalization of a famous number-theoretic problem. There are some notable examples of problems that seemed at first to be number-theoretic, but which were solved by proving a far more general result and ignoring all the number theory. But after a while, one realizes that this is not the right reaction to this problem. Suppose that it were the case that for infinitely many primes equal to mod  (so that was a nonresidue) all the numbers between and were quadratic residues. Then all the combinatorial arguments that we threw at the sets defined earlier would be guaranteed not to work. (In this case, the set would be
(so that was a nonresidue) all the numbers between and were quadratic residues. Then all the combinatorial arguments that we threw at the sets defined earlier would be guaranteed not to work. (In this case, the set would be 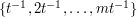 if was a quadratic residue and
if was a quadratic residue and 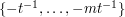 if was a quadratic nonresidue, and all sets would be contained in the set of quadratic residues.)
if was a quadratic nonresidue, and all sets would be contained in the set of quadratic residues.)
This is not a rigorous thing to say, but it is as though the above thought experiment is proving that no combinatorial argument can work because there is a model in which the result is false. We don't actually know that that model exists, and indeed we suspect that it doesn't, but somehow the combinatorial arguments "don't see" whether or not it exists.
A less fanciful way of putting this is as follows. If you try to prove the original combinatorial conjecture, you have to ask yourself, "How am I dealing with, or getting round, the number-theoretic difficulties?" or "If I imagine to be the set of quadratic residues for some prime where there is a very long interval of them, then how does my argument apply to that set and get a contradiction?" If you do not have good answers to these questions, then your approach is unlikely to work.
General discussion
Example 7 illustrates a common phenomenon. Sometimes when you are trying to prove a general theorem, you can prove it easily for any given example and the difficulties arise only when you try to find a general argument that will deal with all examples at once. But sometimes one comes across a single example for which it seems to be very hard to prove that the theorem holds. If that happens, it may still be best to think about the general problem: for instance, the example might just be an instance of the problem that is complicated enough not to have any special features that make it easier to solve. But sometimes it is clear that the natural approach to the single example is very different from the natural approach to the general theorem. In that case, it may be hard to make any progress on the general theorem until one has sorted out the specific example. At the very least, the example will be an extremely good test case: any lemma that one might hope to prove has to be true of the example, any heuristic explanation for why the result is likely to be true has to explain why it is likely to be true of the example, and so on.
Example 8: a conjecture of Erdős
Here is a rather similar example to the previous one. The following is a famous conjecture of Erdős: for every constant and every infinite sequence 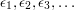 with each
with each 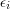 equal to or there exist and
equal to or there exist and 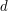 such that
such that 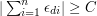 .
.
Again, there is an observation that makes this question seem less obviously combinatorial. Suppose that the sequence is multiplicative, in the sense that 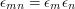 for every and . Then
for every and . Then 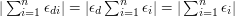 for any and . Therefore, a consequence of Erdős's conjecture is that the partial sums of a multiplicative sequence of s and s cannot be bounded. Moreover, there is a large supply of such sequences: for each prime you can choose
for any and . Therefore, a consequence of Erdős's conjecture is that the partial sums of a multiplicative sequence of s and s cannot be bounded. Moreover, there is a large supply of such sequences: for each prime you can choose 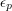 arbitrarily, and then multiplicativity tells you what has to be given the prime factorization of . In particular, if you set
arbitrarily, and then multiplicativity tells you what has to be given the prime factorization of . In particular, if you set 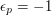 for every , then you get the Möbius function
for every , then you get the Möbius function 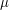 .
.
Partial sums of the Möbius function are notoriously hard to understand: indeed, the assertion that the sum up to doesn't grow much faster than 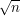 is equivalent to the Riemann hypothesis. This does not mean that Erdős's conjecture would imply the Riemann hypothesis, since it is asking one to prove something much weaker, which is known for the Möbius function. (Odlyzko and te Riele proved in 1985 that the partial sum is infinitely often greater than
is equivalent to the Riemann hypothesis. This does not mean that Erdős's conjecture would imply the Riemann hypothesis, since it is asking one to prove something much weaker, which is known for the Möbius function. (Odlyzko and te Riele proved in 1985 that the partial sum is infinitely often greater than 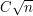 for an explicit constant
for an explicit constant 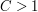 , disproving a conjecture of Mertens.) Nevertheless, the fact that the conjecture has number-theoretic consequences of this kind does again provide one with tests to apply to possible approaches.
, disproving a conjecture of Mertens.) Nevertheless, the fact that the conjecture has number-theoretic consequences of this kind does again provide one with tests to apply to possible approaches.
Another remark to make about this conjecture is that these number-theoretic examples can be slightly misleading because they suggest that a stronger result might be true when in fact it is not. The stronger result would be that we can always find and such that 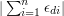 is comparable to . However, examples are known where it is as small as . These examples are again very informative because they prove that "random sequences are not best possible". They also rule out a number of approaches that would naturally give bounds.
is comparable to . However, examples are known where it is as small as . These examples are again very informative because they prove that "random sequences are not best possible". They also rule out a number of approaches that would naturally give bounds.
Here is perhaps the simplest example (which was thought of and told to me by Mark Walters, though he probably wasn't the first). You define to be if the last non-zero digit of is a 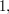 and if the last non-zero digit is a
and if the last non-zero digit is a 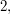 when is written in its base-3 representation. To see why this works, think of it as a sum of infinitely many
when is written in its base-3 representation. To see why this works, think of it as a sum of infinitely many 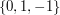 -valued sequences as follows:♦
-valued sequences as follows:♦
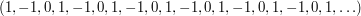
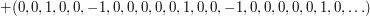
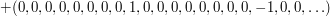
Observe also that it is multiplicative. Therefore, it is enough to check that the partial sums grow no faster than logarithmically, which is the case since the partial sums of each of the above sequences are always either or and at most 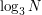 of them make any contribution up to
of them make any contribution up to 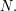
The first sequence on its own destroys a number of possible methods of proof. It would be nice to be able to generalize the result to any sequence that is sufficiently large on average, rather than just a sequence that takes the values 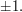 But the sequence
But the sequence 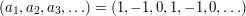 has the property that all partial sums
has the property that all partial sums 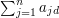 are equal to or
are equal to or 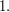 So it seems that average largeness is not enough and one must somehow use largeness everywhere.
So it seems that average largeness is not enough and one must somehow use largeness everywhere.
Comments
Inline comments
The following comments were made inline in the article. You can click on 'view commented text' to see precisely where they were made.
Writing "2 times 3" as "2.3"
Sat, 18/04/2009 - 14:18 — JS (not verified)Writing "2 times 3" as "2.3" is a bit confusing; perhaps you could use "2
Is it clear that these can't be factored any further?
Mon, 15/06/2009 - 19:23 — Michael Lugo (not verified)Is it clear to the intended reader that none of those numbers can be factored any further? Of course one does something like trial division, but it's not obvious what "something like trial division" is.
One possible proof that 2, 3, 1 + \sqrt{-5}, 1 - \sqrt{-5} can't be factored any further is as follows. Let N(a+b\sqrt{-5}) = a^2 + 5b^2 (I use N because this is a "norm".) This norm is multiplicative, since it's the square of the complex absolute value. Then if, say, there exist non-unit elements of Z(\sqrt{-5}), a + b\sqrt{-5} and c + d\sqrt{-5}, such that
(a + b \sqrt{-5}) (c + d \sqrt{-5}) = 3
then they have norms either 1 and 9 or 3 and 3, respectively. There are no elements of the ring with norm 3, and the only elements of norm 1 are units. Similar proofs work for 2, 1 + \sqrt{-5}, 1 - \sqrt{-5} – in general, if an element of Z(\sqrt{-5}) can be factored, then its norm can be factored, and the factorization of a + b\sqrt{-5} will be a "lifting" of the factorization of the norm a^2 + 5b^2.
("Take norms" seems like its own trick, and perhaps this is better placed in an article on that trick.)
This is a nice comment of
Mon, 15/06/2009 - 19:42 — gowersThis is a nice comment of yours, and it does seem to me that the best thing to do Tricki-wise is what you more or less suggest. That is, in this article one could say something like, "It is not hard to prove that the numbers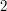 ,
, 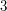 and
and 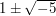 cannot be factorized any further" and then say "For a proof, see ..." Then there could be a separate article on this norm trick. Or perhaps the norm trick could be thought of as an example of the more general trick, which actually came up in a discussion about proving facts about groups, of finding a homomorphism to some structure that's simpler to analyse.
cannot be factorized any further" and then say "For a proof, see ..." Then there could be a separate article on this norm trick. Or perhaps the norm trick could be thought of as an example of the more general trick, which actually came up in a discussion about proving facts about groups, of finding a homomorphism to some structure that's simpler to analyse.
Inline comments
The following comments were made inline in the article. You can click on 'view commented text' to see precisely where they were made.
Use of measure theory is question-begging?
Sun, 19/04/2009 - 19:50 — Anonymous (not verified)You're assuming here that one is not yet convinced that measure theory is correct. This is an odd assumption, and it would be better to state it in the beginning of the problem. As it is, the "this is obvious" reaction is quite right and can be made rigorous with straightforward use of the Lebesgue measure. (rationals are a whole different kettle of fish of course, being a null set)
That's not quite what I'm
Sun, 19/04/2009 - 22:56 — gowersThat's not quite what I'm doing. If we accept the dictum that a statement is obvious if a proof instantly springs to mind, then this statement is certainly obvious modulo Lebesgue measure: that is, the proof instantly springs to mind that the measure of the resulting union is too small. But the consistency of the definition of Lebesgue measure is not itself obvious. What I am arguing here is that there is no simple proof from first principles. I think the title of the section makes it fairly clear that we start from the position that Lebesgue measure is not yet established.
Inline comments
The following comments were made inline in the article. You can click on 'view commented text' to see precisely where they were made.
This isn't too significant,
Mon, 20/04/2009 - 04:53 — Kevin VentulloThis isn't too significant, but I think it would help to mention that you're working in base 3 here.
Oops – thanks! I've
Mon, 20/04/2009 - 07:00 — gowersOops – thanks! I've added that in now.
Inline comments
The following comments were made inline in the article. You can click on 'view commented text' to see precisely where they were made.
Why is this "best"?
Mon, 22/06/2009 - 17:41 — mckeown_j.cDoes it mean the re-write needed to see "variance" is small? Or is it because "partition" naturally suggests "statistics"?
There are reasons to prefer habitually testing for Cauchy-Schwartz, or even Jensen's inequality: for instance they are both more flexible than "variance".
Post new comment
(Note: commenting is not possible on this snapshot.)