Quick description
Sometimes a very simple and efficient way of carrying out an algorithmic task is to make random choices. Indeed, there are many examples of tasks that have easy and fast randomized algorithms but no known efficient deterministic algorithms. The obvious disadvantage of randomization, that one cannot be certain that the algorithm will do what one wants, is in many situations not too important, since one can arrange for the probability of failure to be so small that in practice it is negligible. This article contains one very simple example of a randomized algorithm to illustrate the basic idea, and gives links to articles about randomized algorithms of various different types.
Example 1
Click here for the example ( A Boolean function is a function 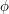 from
from 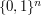 to
to 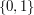 . That is, takes as its input a string of
. That is, takes as its input a string of 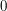 s and
s and 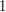 s of length
s of length  and outputs either or . By focusing our attention on the set
and outputs either or . By focusing our attention on the set 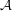 of strings where takes the value 1. Suppose that you are presented with a function and asked to estimate the size of . And suppose also that you do not understand well enough to be able to tell for theoretical reasons even roughly how big is. What can you do?
If is very small, then you can simply work out
of strings where takes the value 1. Suppose that you are presented with a function and asked to estimate the size of . And suppose also that you do not understand well enough to be able to tell for theoretical reasons even roughly how big is. What can you do?
If is very small, then you can simply work out 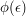 for all the strings
for all the strings 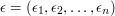 and see how often you get 1. But if
and see how often you get 1. But if 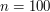 , say, then this will take your computer far too long. However, there is a very easy way of getting round this problem if you are ready to make two small sacrifices: you will not try to find the exact answer, but just an approximation, and you will accept a very small probability that even the approximation will be wrong.
In that case, you can simply choose
, say, then this will take your computer far too long. However, there is a very easy way of getting round this problem if you are ready to make two small sacrifices: you will not try to find the exact answer, but just an approximation, and you will accept a very small probability that even the approximation will be wrong.
In that case, you can simply choose 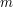 random strings (where the larger is, the better your approximation will be and the smaller the probability that you do not get a good approximation), work out for each string, and estimate that the proportion of strings for which
random strings (where the larger is, the better your approximation will be and the smaller the probability that you do not get a good approximation), work out for each string, and estimate that the proportion of strings for which 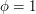 is the proportion of the strings you have chosen for which
is the proportion of the strings you have chosen for which 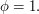 To see why that works, let us suppose that
To see why that works, let us suppose that 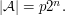 That is, the proportion of strings
That is, the proportion of strings  for which
for which 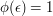 is
is 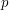 . Then if we choose random strings, the number of those strings for which is binomially distributed with parameters and . For any fixed
. Then if we choose random strings, the number of those strings for which is binomially distributed with parameters and . For any fixed 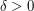 it can be shown that the probability that a binomial variable with parameters and differs by more than
it can be shown that the probability that a binomial variable with parameters and differs by more than 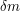 from its mean
from its mean 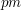 is at most
is at most 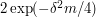 . (See Example 3 of the article on bounding probabilities by expectations for a proof.) Therefore, if we want to estimate to within
. (See Example 3 of the article on bounding probabilities by expectations for a proof.) Therefore, if we want to estimate to within 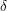 and are prepared to accept a probability
and are prepared to accept a probability 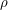 of failure, then we can take to be
of failure, then we can take to be 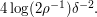 Note that this does not even depend on . )
Note that this does not even depend on . )
Specific kinds of randomized algorithm
Elementary randomized algorithms Brief summary ( This article is about algorithms that, like the example above, exploit the fact that repeated trials of the same experiment almost always give rise to the same approximate behaviour in the long term. A famous example of such an algorithm is the randomized algorithm of Miller and Rabin for testing whether a positive integer is prime. )
Random sampling using Markov chains Brief summary ( Suppose that you want to generate, uniformly at random, some combinatorial structure or substructure. If the structure is simple enough, then there may be an easy way of converting random bits into the structure you want, with the correct distribution. For example, to choose a random graph one can just pick each edge independently at random with probability 1/2. However, a trivial direct approach like this is often not possible: how, for example, would you choose a (labelled) tree uniformly at random? A commonly used technique in more difficult situations is to take a random walk through the "space" of all objects of interest and to prove that the walk is rapidly mixing, which means that after not too long the distribution of where the walk has reached is approximately uniform. )
Comments
Post new comment
(Note: commenting is not possible on this snapshot.)