 |
Quick description
Suppose that 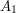 ,
, 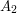 ,...,
,..., 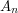 are events and you want to calculate the probability that at least one
are events and you want to calculate the probability that at least one 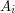 holds. In set-theoretic terms, we are trying to calculate
holds. In set-theoretic terms, we are trying to calculate 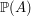 , where
, where 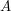 is the union
is the union 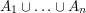 of these events. If the events overlap, this may look difficult, but often it can be computed using the inclusion-exclusion principle, which states that
of these events. If the events overlap, this may look difficult, but often it can be computed using the inclusion-exclusion principle, which states that
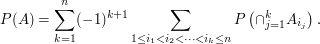
Although this formula appears complicated, what it gives is a way of calculating the probability of a union if you know the probabilities of intersections. Thus, for the method to be useful, it must be simple to compute the probabilities of the intersections 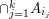 .
.
Prerequisites
Elementary probability theory.
Example 1
General discussion
Almost all expectation/probability computations can be embedded into a larger problem of a family of problems of the same kind and the larger problem will give a recursion [a reference to an article on this principle]. Sometimes, this recursion is not particularly simple to study. This will happen if the event has no simple sequential description, i.e., an algorithm that generates its elements. What we mean by `not simple' in the preceding sentence is this: the probability of the set of all possible ways to execute the 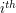 step of this description/algorithm depends in a complicated way on the previous steps [ reference to the examples]. The inclusion/exclusion principle can be especially useful in such situations.
step of this description/algorithm depends in a complicated way on the previous steps [ reference to the examples]. The inclusion/exclusion principle can be especially useful in such situations.
We also note that inclusion/exclusion is a representation result: it gives the probability of exactly in terms of the probability of intersections of the sets whose union is . This is interesting for several reasons. First, there aren't many results that allow one to compute a probability exactly. Second, using the inclusion exclusion principle in a theoretical or computational argument causes no loss of information.
Comments
Post new comment
(Note: commenting is not possible on this snapshot.)