 |
Quick description
When trying to quickly work out what an exponent 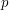 in an estimate, identity, or inequality should be without deriving that statement line-by-line, test that statement with a simple example which has non-trivial behaviour with respect to that exponent , but trivial behaviour with respect to as many other components of that statement as one is able to manage. The "non-trivial" behaviour should be parametrised by some very large or very small parameter. By matching the dependence on this parameter on both sides of the estimate, identity, or inequality, one should recover (or at least a good prediction as to what should be).
in an estimate, identity, or inequality should be without deriving that statement line-by-line, test that statement with a simple example which has non-trivial behaviour with respect to that exponent , but trivial behaviour with respect to as many other components of that statement as one is able to manage. The "non-trivial" behaviour should be parametrised by some very large or very small parameter. By matching the dependence on this parameter on both sides of the estimate, identity, or inequality, one should recover (or at least a good prediction as to what should be).
Prerequisites
Undergraduate analysis and combinatorics.
Motivation
In the more quantitative areas of mathematics, such as analysis and combinatorics, one has to frequently keep track of a large number of exponents in one's identities, inequalities, and estimates. For instance, if one is studying a set of 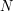 elements, then many expressions that one is faced with will often involve some power
elements, then many expressions that one is faced with will often involve some power 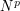 of ; if one is instead studying a function
of ; if one is instead studying a function 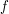 on a measure space
on a measure space 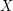 , then perhaps it is an
, then perhaps it is an 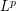 norm
norm 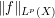 which will appear instead. The exponent involved will typically evolve slowly over the course of the argument, as various algebraic or analytic manipulations are applied. In some cases, the exact value of this exponent is immaterial, but at other times it is crucial to have the correct value of at hand. One can (and should) of course carefully go through one's arguments line by line to work out the exponents correctly, but it is all too easy to make a sign error or other mis-step at one of the lines, causing all the exponents on subsequent lines to be incorrect. However, one can guard against this (and avoid some tedious line-by-line exponent checking) by continually calibrating these exponents at key junctures of the arguments by using basic examples of the object of study (sets, functions, graphs, etc.) as test cases. This is a simple trick, but it lets one avoid many unforced errors with exponents, and also lets one compute more rapidly.
which will appear instead. The exponent involved will typically evolve slowly over the course of the argument, as various algebraic or analytic manipulations are applied. In some cases, the exact value of this exponent is immaterial, but at other times it is crucial to have the correct value of at hand. One can (and should) of course carefully go through one's arguments line by line to work out the exponents correctly, but it is all too easy to make a sign error or other mis-step at one of the lines, causing all the exponents on subsequent lines to be incorrect. However, one can guard against this (and avoid some tedious line-by-line exponent checking) by continually calibrating these exponents at key junctures of the arguments by using basic examples of the object of study (sets, functions, graphs, etc.) as test cases. This is a simple trick, but it lets one avoid many unforced errors with exponents, and also lets one compute more rapidly.
General discussion
The test examples should be as basic as possible; ideally they should have trivial behaviour in all aspects except for one feature that relates to the exponent that one is trying to calibrate, thus being only "barely" non-trivial. When the object of study is a function, then (appropriately rescaled, or otherwise modified) bump functions are very typical test objects, as are Dirac masses, constant functions, Gaussians, or other functions that are simple and easy to compute with. In additive combinatorics, when the object of study is a subset of a group, then subgroups, arithmetic progressions, or random sets are typical test objects. In graph theory, typical examples of test objects include complete graphs, complete bipartite graphs, and random graphs. And so forth.
This trick is closely related to that of using dimensional analysis to recover exponents; indeed, one can view dimensional analysis as the special case of exponent calibration when using test objects which are non-trivial in one dimensional aspect (e.g. they exist at a single very large or very small length scale) but are otherwise of a trivial or "featureless" nature. But the calibration trick is more general, as it can involve parameters (such as probabilities, angles, or eccentricities) which are not commonly associated with the physical concept of a dimension. And personally, I find example-based calibration to be a much more satisfying (and convincing) explanation of an exponent than a calibration arising from formal dimensional analysis.
When one is trying to calibrate an inequality or estimate, one should try to pick a basic example which one expects to saturate that inequality or estimate, i.e. an example for which the inequality is close to being an equality. Otherwise, one would only expect to obtain some partial information on the desired exponent (e.g. a lower bound or an upper bound only). Knowing the examples that saturate an estimate that one is trying to prove is also useful for several other reasons - for instance, it strongly suggests that any technique which is not efficient when applied to the saturating example, is unlikely to be strong enough to prove the estimate in general, thus eliminating fruitless approaches to a problem and (hopefully) refocusing one's attention on those strategies which actually have a chance of working.
Calibration is best used for the type of quick-and-dirty calculations one uses when trying to rapidly map out an argument that one has roughly worked out already, but without precise details; in particular, I find it particularly useful when writing up a rapid prototype. When the time comes to write out the paper in full detail, then of course one should instead carefully work things out line by line, but if all goes well, the exponents obtained in that process should match up with the preliminary guesses for those exponents obtained by calibration, which adds confidence that there are no exponent errors have been committed.
Example 1
(Elementary identities) There is a familiar identity for the sum of the first  squares:
squares:
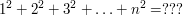 (1)
(1)
But imagine that one has forgotten exactly what the RHS of (1) was supposed to be... one remembers that it was some polynomial in , but can't remember what the degree or coefficients of the polynomial were. Now one can of course try to rederive the identity, but there are faster (albeit looser) ways to reconstruct the right-hand side. Firstly, we can look at the asymptotic test case 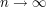 . On the LHS, we are summing n terms of size at most
. On the LHS, we are summing n terms of size at most 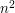 , so the LHS is at most
, so the LHS is at most 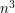 ; thus, if we believe the RHS to be a polynomial in , it should be at most cubic in . We can do a bit better by approximating the sum in the LHS by the integral
; thus, if we believe the RHS to be a polynomial in , it should be at most cubic in . We can do a bit better by approximating the sum in the LHS by the integral 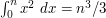 , which strongly suggests that the cubic term on the RHS should be
, which strongly suggests that the cubic term on the RHS should be 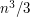 . So now we have
. So now we have
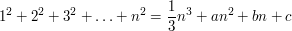
for some coefficients  ,
,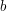 ,
, that we still have to work out.
that we still have to work out.
We can plug in some other basic cases. A simple one is 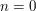 . The LHS is now zero, and so the constant coefficient on the RHS should also vanish. A slightly less obvious base case is
. The LHS is now zero, and so the constant coefficient on the RHS should also vanish. A slightly less obvious base case is 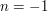 . The LHS is still zero (note that the LHS for
. The LHS is still zero (note that the LHS for 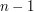 should be the LHS for , minus ), and so the RHS still vanishes here; thus by the factor theorem, the RHS should have both and
should be the LHS for , minus ), and so the RHS still vanishes here; thus by the factor theorem, the RHS should have both and 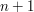 as factors. We are now looking at
as factors. We are now looking at
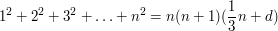
for some unspecified constant 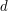 . But now we just need to try one more test case, e.g.
. But now we just need to try one more test case, e.g. 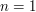 , and we learn that
, and we learn that 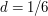 , thus recovering the correct formula
, thus recovering the correct formula
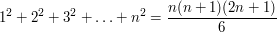 . (1')
. (1')
Once one has the formula (1') in hand, of course, it is not difficult to verify by a textbook use of mathematical induction that the formula is in fact valid. (Alternatively, one can prove a more abstract theorem that the sum of the first 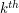 powers is necessarily a polynomial in for any given
powers is necessarily a polynomial in for any given 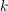 , at which point the above analysis actually becomes a rigorous derivation of (1').)
, at which point the above analysis actually becomes a rigorous derivation of (1').)
Note that the optimal strategy here is to start with the most basic test cases (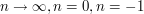 ) first before moving on to less trivial cases. If instead one used, e.g. ,
) first before moving on to less trivial cases. If instead one used, e.g. , 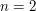 ,
, 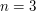 ,
, 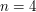 as the test cases, one would eventually have obtained the right answer, but it would have been more work.
as the test cases, one would eventually have obtained the right answer, but it would have been more work.
Exercise
(Partial fractions) If 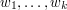 are distinct complex numbers, and
are distinct complex numbers, and 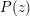 is a polynomial of degree less than , establish the existence of a partial fraction decomposition
is a polynomial of degree less than , establish the existence of a partial fraction decomposition
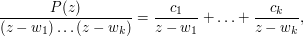
(Hint: use the remainder theorem and induction) and use the test cases 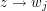 for
for 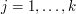 to compute the coefficients
to compute the coefficients 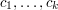 . Use this to deduce the Lagrange interpolation formula.
. Use this to deduce the Lagrange interpolation formula. 
Example 2
(Counting cycles in a graph) Suppose one has a graph 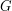 on vertices with an edge density of
on vertices with an edge density of 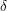 (thus, the number of edges is
(thus, the number of edges is 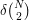 , or roughly
, or roughly 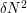 up to constants). There is a standard Cauchy-Schwarz argument that gives a lower bound on the number of four-cycles
up to constants). There is a standard Cauchy-Schwarz argument that gives a lower bound on the number of four-cycles 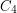 (i.e. a circuit of four vertices connected by four edges) present in , as a function of and . It only takes a few minutes to reconstruct this argument to obtain the precise bound, but suppose one was in a hurry and wanted to guess the bound rapidly. Given the "polynomial" nature of the Cauchy-Schwarz inequality, the bound is likely to be some polynomial combination of and , such as
(i.e. a circuit of four vertices connected by four edges) present in , as a function of and . It only takes a few minutes to reconstruct this argument to obtain the precise bound, but suppose one was in a hurry and wanted to guess the bound rapidly. Given the "polynomial" nature of the Cauchy-Schwarz inequality, the bound is likely to be some polynomial combination of and , such as 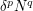 (omitting constants and lower order terms). But what should and
(omitting constants and lower order terms). But what should and 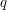 be?
be?
Well, one can test things with some basic examples. A really trivial example is the empty graph (where 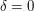 ), but this is too trivial to tell us anything much (other than that should probably be positive). At the other extreme, consider the complete graph on vertices, where
), but this is too trivial to tell us anything much (other than that should probably be positive). At the other extreme, consider the complete graph on vertices, where 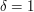 ; this renders irrelevant, but still makes non-trivial (and thus, hopefully, computable). In the complete graph, every set of four points yields a four-cycle , so the number of four-cycles here should be about
; this renders irrelevant, but still makes non-trivial (and thus, hopefully, computable). In the complete graph, every set of four points yields a four-cycle , so the number of four-cycles here should be about 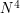 (give or take some constant factors, such as
(give or take some constant factors, such as 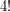 - remember that we are in a hurry here, and are ignoring these sorts of constant factors). This tells us that should be at most
- remember that we are in a hurry here, and are ignoring these sorts of constant factors). This tells us that should be at most  , and if we expect the Cauchy-Schwarz bound to be saturated for the complete graph (which is a good bet - arguments based on the Cauchy-Schwarz inequality tend to work well in very "uniformly distributed" situations) - then we would expect to be exactly .
, and if we expect the Cauchy-Schwarz bound to be saturated for the complete graph (which is a good bet - arguments based on the Cauchy-Schwarz inequality tend to work well in very "uniformly distributed" situations) - then we would expect to be exactly .
To calibrate , we need to test with graphs of density less than 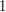 . Given the previous intuition that Cauchy-Schwarz arguments work well in uniformly distributed situations, we would want to use a test graph of density that is more or less uniformly distributed. A good example of such a graph is a random graph on vertices, in which each edge has an independent probability of of lying in . By the law of large numbers, we expect the edge density of such a random graph to be close to on the average. On the other hand, each one of the roughly four-cycles connecting the vertices has a probability about
. Given the previous intuition that Cauchy-Schwarz arguments work well in uniformly distributed situations, we would want to use a test graph of density that is more or less uniformly distributed. A good example of such a graph is a random graph on vertices, in which each edge has an independent probability of of lying in . By the law of large numbers, we expect the edge density of such a random graph to be close to on the average. On the other hand, each one of the roughly four-cycles connecting the vertices has a probability about 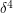 of lying in the graph, since the has four edges, each with an independent probability of of lying in the edge. The events that each of the four-cycles lies in the graph aren't completely independent of each other, but they are still close enough to being so that one can guess using the law of large numbers that the total number of -cycles should be about
of lying in the graph, since the has four edges, each with an independent probability of of lying in the edge. The events that each of the four-cycles lies in the graph aren't completely independent of each other, but they are still close enough to being so that one can guess using the law of large numbers that the total number of -cycles should be about 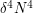 on the average (up to constants). [Actually, linearity of expectation will give us this claim even without any independence whatsoever.] So this leads one to predict
on the average (up to constants). [Actually, linearity of expectation will give us this claim even without any independence whatsoever.] So this leads one to predict 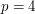 , thus the number of -cycles in any graph on vertices of density should be
, thus the number of -cycles in any graph on vertices of density should be 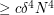 for some absolute constant
for some absolute constant 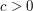 , and this is indeed the case (provided that one also counts degenerate cycles, in which some vertices are repeated).
, and this is indeed the case (provided that one also counts degenerate cycles, in which some vertices are repeated).
If one is nervous about using the random graph as the test graph, one could try a graph at the other end of the spectrum - e.g. the complete graph on about 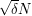 vertices, which also has edge density about . Here one quickly calculates that the number of -cycles is about
vertices, which also has edge density about . Here one quickly calculates that the number of -cycles is about 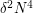 , which is a larger quantity than in the random case (and this fits with the intuition that this graph is packing the same number of edges into a tighter space, and should thus increase the number of cycles). So the random graph is still the best candidate for a near-extremiser for this bound. (Actually, if the number of -cycles is close to the Cauchy-Schwarz lower bound, then the graph becomes pseudorandom, which roughly speaking means any randomly selected small subgraph of that graph is indistinguishable from a random graph.)
, which is a larger quantity than in the random case (and this fits with the intuition that this graph is packing the same number of edges into a tighter space, and should thus increase the number of cycles). So the random graph is still the best candidate for a near-extremiser for this bound. (Actually, if the number of -cycles is close to the Cauchy-Schwarz lower bound, then the graph becomes pseudorandom, which roughly speaking means any randomly selected small subgraph of that graph is indistinguishable from a random graph.)
One should caution that sometimes the random object is not the extremiser, and so does not always calibrate an estimate correctly. For instance, consider Szemerédi's theorem, that asserts that given any 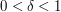 and
and 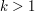 , that any subset of
, that any subset of 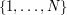 of density should contain at least one arithmetic progression of length , if is large enough. One can then ask what is the minimum number of -term arithmetic progressions such a set would contain. Using the random subset of of density as a test case, we would guess that there should be about
of density should contain at least one arithmetic progression of length , if is large enough. One can then ask what is the minimum number of -term arithmetic progressions such a set would contain. Using the random subset of of density as a test case, we would guess that there should be about 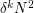 (up to constants depending on ). However, it turns out that the number of progressions can be significantly less than this (basically thanks to the old counterexample of Behrend): given any constant
(up to constants depending on ). However, it turns out that the number of progressions can be significantly less than this (basically thanks to the old counterexample of Behrend): given any constant 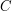 , one can get significantly fewer than
, one can get significantly fewer than 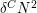 -term progressions. But, thanks to an averaging argument of Varnavides, it is known that there are at least
-term progressions. But, thanks to an averaging argument of Varnavides, it is known that there are at least 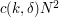 -term progressions (for large enough), where
-term progressions (for large enough), where 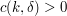 is a positive quantity. (Determining the exact order of magnitude of
is a positive quantity. (Determining the exact order of magnitude of 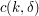 is still an important open problem in this subject.) So one can at least calibrate the correct dependence on , even if the dependence on is still unknown.
is still an important open problem in this subject.) So one can at least calibrate the correct dependence on , even if the dependence on is still unknown.
Example 3
Example 3. (Sobolev embedding) Given a reasonable function 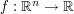 (e.g. a Schwartz class function will do), the Sobolev embedding theorem gives estimates such as
(e.g. a Schwartz class function will do), the Sobolev embedding theorem gives estimates such as
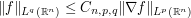 (2)
(2)
for various exponents , . Suppose one has forgotten the exact relationship between , , and and wants to quickly reconstruct it, without rederiving the proof of the theorem or looking it up. One could use dimensional analysis to work out the relationship (and we will come to that shortly), but an equivalent way to achieve the same result is to test the inequality (2) against a suitably basic example, preferably one that one expects to saturate (2).
To come as close to saturating (2) as possible, one wants to keep the gradient of small, while making large; among other things, this suggests that unnecessary oscillations in should be kept to a minimum. A natural candidate for an extremiser, then, would be a rescaled bump function 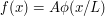 , where
, where 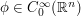 is some fixed bump function,
is some fixed bump function, 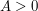 is an amplitude parameter, and
is an amplitude parameter, and 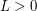 is a parameter, thus is a rescaled bump function of bounded amplitude
is a parameter, thus is a rescaled bump function of bounded amplitude 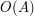 that is supported on a ball of radius
that is supported on a ball of radius 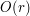 centred at the origin. [As the estimate (2) is linear, the amplitude
centred at the origin. [As the estimate (2) is linear, the amplitude 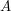 turns out to ultimately be irrelevant here, but the amplitude plays a more crucial role in nonlinear estimates; for instance, it explains why nonlinear estimates typically have the same number of appearances of a given unknown function in each term. Also, it is sometimes convenient to carefully choose the amplitude in order to attain a convenient normalisation, e.g. to set one of the norms in (2) equal to .]
turns out to ultimately be irrelevant here, but the amplitude plays a more crucial role in nonlinear estimates; for instance, it explains why nonlinear estimates typically have the same number of appearances of a given unknown function in each term. Also, it is sometimes convenient to carefully choose the amplitude in order to attain a convenient normalisation, e.g. to set one of the norms in (2) equal to .]
The ball that is supported on has volume about 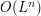 (allowing implied constants to depend on ), and so the
(allowing implied constants to depend on ), and so the 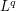 norm of should be about
norm of should be about 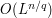 (allowing implied constants to depend on as well). As for the gradient of , since oscillates by over a length scale of
(allowing implied constants to depend on as well). As for the gradient of , since oscillates by over a length scale of 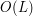 , one expects
, one expects 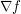 to have size about
to have size about 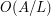 on this ball (remember, derivatives measure "rise over run"!), and so the norm of should be about
on this ball (remember, derivatives measure "rise over run"!), and so the norm of should be about 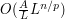 . Inserting this numerology into (2), and equating powers of
. Inserting this numerology into (2), and equating powers of 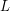 (note cancels itself into irrelevance, and could in any case be set to equal ), we are led to the relation
(note cancels itself into irrelevance, and could in any case be set to equal ), we are led to the relation
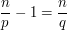 (2)
(2)
which is indeed one of the necessary conditions for (2). (The other necessary conditions are that and lie strictly between and infinity, but these require a more complicated test example to establish.)
One can efficiently perform the above argument using the language of dimensional analysis. Giving the units of amplitude , and giving space the units of length , we see that the -dimensional integral 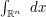 has units of
has units of 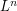 , and thus
, and thus 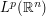 norms have units of
norms have units of 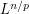 . Meanwhile, from the rise-over-run interpretation of the derivative, has units of
. Meanwhile, from the rise-over-run interpretation of the derivative, has units of 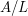 , thus the LHS and RHS of (2) have units of
, thus the LHS and RHS of (2) have units of 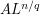 and
and 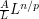 respectively. Equating these dimensions gives (3). Observe how this argument is basically a shorthand form of the argument based on using the rescaled bump function as a test case; with enough practice one can use this shorthand to calibrate exponents rapidly for a wide variety of estimates.
respectively. Equating these dimensions gives (3). Observe how this argument is basically a shorthand form of the argument based on using the rescaled bump function as a test case; with enough practice one can use this shorthand to calibrate exponents rapidly for a wide variety of estimates.
Exercise
Convert the above discussion into a rigorous proof that (3) is a necessary condition for (2). (Hint: exploit the freedom to send to zero or to infinity.) What happens to the necessary conditions if 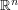 is replaced with a bounded domain (such as the unit cube
is replaced with a bounded domain (such as the unit cube ![{}[0,1]^n](../images/tex/84b89898e4979cc4b7e7f7d14a42aa73.png) , assuming Dirichlet boundary conditions) or a discrete domain (such as the lattice
, assuming Dirichlet boundary conditions) or a discrete domain (such as the lattice 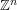 , replacing the gradient with a discrete gradient of course)?
, replacing the gradient with a discrete gradient of course)?
Exercise
If one replaces (2) by the variant estimate
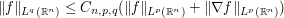 (2')
(2')
establish the necessary condition
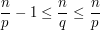 . (3')
. (3')
What happens to the dimensional analysis argument in this case?
Remark
There are many other estimates in harmonic analysis which are saturated by some modification of a bump function; in addition to the isotropically rescaled bump functions used above, one could also rescale bump functions by some non-isotropic linear transformation (thus creating various "squashed" or "stretched" bumps adapted to disks, tubes, rectangles, or other sets), or modulate bumps by various frequencies, or translate them around in space. One can also try to superimpose several such transformed bump functions together to amplify the counterexample. The art of selecting good counterexamples can be somewhat difficult, although with enough trial and error one gets a sense of what kind of arrangement of bump functions are needed to make the right-hand side small and the left-hand side large in the estimate under study.
Example 4
(Scale-invariance in nonlinear PDE) The model equations and systems studied in nonlinear PDE often enjoy various symmetries, notably scale-invariance symmetry, that can then be used to calibrate various identities and estimates regarding solutions to those equations. For sake of discussion, let us work with the nonlinear Schrödinger equation (NLS)
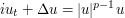 (4)
(4)
where 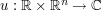 is the unknown field,
is the unknown field, 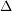 is the spatial Laplacian, and
is the spatial Laplacian, and 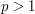 is a fixed exponent. (One can also place in some other constants in (4), such as Planck's constant
is a fixed exponent. (One can also place in some other constants in (4), such as Planck's constant 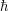 , but we have normalised this constant to equal here, although it is sometimes useful to reinstate this constant for calibration purposes.) If
, but we have normalised this constant to equal here, although it is sometimes useful to reinstate this constant for calibration purposes.) If  is one solution to (4), then we can form a rescaled family
is one solution to (4), then we can form a rescaled family 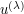 of such solutions by the formula
of such solutions by the formula
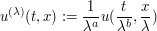 (5)
(5)
for some specific exponents , ; these play the role of the rescaled bump functions in Example 2. The exponents , can be worked out by testing (4) using (5), and we leave this as an exercise to the reader, but let us instead use the shorthand of dimensional analysis to work these exponents out. Let's give the units of amplitude , space the units of length , and time the units of duration 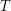 . Then the three terms in (4) have units
. Then the three terms in (4) have units 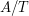 ,
, 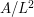 , and
, and 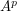 respectively; equating these dimensions gives
respectively; equating these dimensions gives 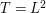 and
and 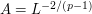 . (In particular, time has "twice the dimension" of space; this is a feature of many non-relativistic equations such as Schrödinger, heat, or viscosity equations. For relativistic equations, of course, time and space have the same dimension with respect to scaling.) On the other hand, the scaling (5) multiplies , , and by
. (In particular, time has "twice the dimension" of space; this is a feature of many non-relativistic equations such as Schrödinger, heat, or viscosity equations. For relativistic equations, of course, time and space have the same dimension with respect to scaling.) On the other hand, the scaling (5) multiplies , , and by 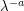 ,
, 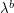 , and
, and 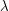 respectively; to maintain consistency with the relations and we must thus have
respectively; to maintain consistency with the relations and we must thus have 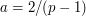 and
and 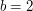 .
.
Exercise
Solutions to (4) (with suitable smoothness and decay properties) enjoy a conserved Hamiltonian 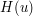 , of the form
, of the form
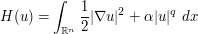
for some constants 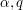 . Use dimensional analysis (or the rescaled solutions (5) as test cases) to compute . (The constant
. Use dimensional analysis (or the rescaled solutions (5) as test cases) to compute . (The constant  , unfortunately, cannot be recovered from dimensional analysis, and other model test cases, such as solitons or other solutions obtained via separation of variables, also turn out unfortunately to not be sensitive enough to to calibrate this parameter.)
, unfortunately, cannot be recovered from dimensional analysis, and other model test cases, such as solitons or other solutions obtained via separation of variables, also turn out unfortunately to not be sensitive enough to to calibrate this parameter.)
Remark
The scaling symmetry (5) is not the only symmetry that can be deployed to calibrate identities and estimates for solutions to NLS. For instance, we have a simple phase rotation symmetry 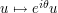 for such solutions, where
for such solutions, where 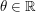 is an arbitrary phase. This symmetry suggests that in any identity involving and its complex conjugate
is an arbitrary phase. This symmetry suggests that in any identity involving and its complex conjugate  , the net number of factors of , minus the factors of , in each term of the identity should be the same. (Factors without phase, such as
, the net number of factors of , minus the factors of , in each term of the identity should be the same. (Factors without phase, such as 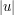 , should be ignored for this analysis.) Other important symmetries of NLS, which can also be used for calibration, include space translation symmetry, time translation symmetry, and Galilean invariance. (While these symmetries can of course be joined together, to create a large-dimensional family of transformed solutions arising from a single base solution , for the purposes of calibration it is usually best to just use each of the generating symmetries separately.) For gauge field equations, gauge invariance is of course a crucial symmetry, though one can make the calibration procedure with respect to this symmetry automatic by working exclusively with gauge-invariant notation (see also my earlier post on gauge theory). Another important test case for Schrödinger equations is the high-frequency limit
, should be ignored for this analysis.) Other important symmetries of NLS, which can also be used for calibration, include space translation symmetry, time translation symmetry, and Galilean invariance. (While these symmetries can of course be joined together, to create a large-dimensional family of transformed solutions arising from a single base solution , for the purposes of calibration it is usually best to just use each of the generating symmetries separately.) For gauge field equations, gauge invariance is of course a crucial symmetry, though one can make the calibration procedure with respect to this symmetry automatic by working exclusively with gauge-invariant notation (see also my earlier post on gauge theory). Another important test case for Schrödinger equations is the high-frequency limit 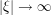 , closely related to the semi-classical limit
, closely related to the semi-classical limit 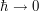 , that allows one to use classical mechanics to calibrate various identities and estimates in quantum mechanics.
, that allows one to use classical mechanics to calibrate various identities and estimates in quantum mechanics.
Exercise
Solutions to (4) (again assuming suitable smoothness and decay) also enjoy a virial identity of the form
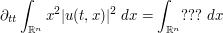
where the right-hand side only involves and its spatial derivatives 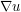 , and does not explicitly involve the spatial variable
, and does not explicitly involve the spatial variable  . Using the various symmetries, predict the type of terms that should go on the right-hand side. (Again, the coefficients of these terms are unable to be calibrated using these methods, but the exponents should be accessible.)
. Using the various symmetries, predict the type of terms that should go on the right-hand side. (Again, the coefficients of these terms are unable to be calibrated using these methods, but the exponents should be accessible.)
Remark
Einstein used this sort of calibration technique (using the symmetry of spacetime diffeomorphisms, better known as the general principle of relativity, as well as the non-relativistic limit of Newtonian gravity as another test case) to derive the Einstein equations of gravity, although the one constant that he was unable to calibrate in this fashion was the cosmological constant.
Example 5
(Fourier-analytic identities in additive combinatorics). Fourier analysis is a useful tool in additive combinatorics for counting various configurations in sets, such as arithmetic progressions 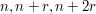 of length three. (It turns out that classical Fourier analysis is not able to handle progressions of any longer length, but that is a story for another time - see e.g. this paper of Gowers for some discussion.) A typical situation arises when working in a finite group such as
of length three. (It turns out that classical Fourier analysis is not able to handle progressions of any longer length, but that is a story for another time - see e.g. this paper of Gowers for some discussion.) A typical situation arises when working in a finite group such as 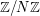 , and one has to compute an expression such as
, and one has to compute an expression such as
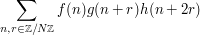 (6)
(6)
for some functions 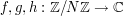 (for instance, these functions could all be the indicator function of a single set
(for instance, these functions could all be the indicator function of a single set 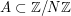 ). The quantity (6) can be expressed neatly in terms of the Fourier transforms
). The quantity (6) can be expressed neatly in terms of the Fourier transforms 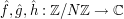 , which we normalise as
, which we normalise as 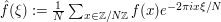 . It is not too difficult to compute this expression by means of the Fourier inversion formula and some routine calculation, but suppose one was in a hurry and only had a vague recollection of what the Fourier-analytic expression of (6) was - something like
. It is not too difficult to compute this expression by means of the Fourier inversion formula and some routine calculation, but suppose one was in a hurry and only had a vague recollection of what the Fourier-analytic expression of (6) was - something like
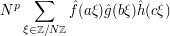 (7)
(7)
for some coefficients , , , , but the precise values of which have been forgotten. (In view of some other Fourier-analytic formulae, one might think that some of the Fourier transforms 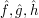 might need to be complex conjugated for (7), but this should not happen here, because (6) is linear in
might need to be complex conjugated for (7), but this should not happen here, because (6) is linear in 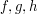 rather than anti-linear; cf. the discussion in Example 3 about factors of and .) How can one quickly calibrate the values of
rather than anti-linear; cf. the discussion in Example 3 about factors of and .) How can one quickly calibrate the values of 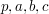 without doing the full calculation?
without doing the full calculation?
To isolate the exponent , we can consider the basic case 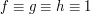 , in which case the Fourier transforms are just the Kronecker delta function (e.g.
, in which case the Fourier transforms are just the Kronecker delta function (e.g. 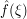 equals 1 for
equals 1 for 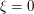 and vanishes otherwise). The expression (6) is just
and vanishes otherwise). The expression (6) is just 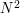 , while the expression (7) is (because only one of the summands is non-trivial); thus must equal
, while the expression (7) is (because only one of the summands is non-trivial); thus must equal 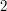 . (Exercise: reinterpret the above analysis as a dimensional analysis.)
. (Exercise: reinterpret the above analysis as a dimensional analysis.)
Next, to calibrate 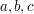 , we modify the above basic test case slightly, modulating the so that a different element of the sum in (7) is non-zero. Let us take
, we modify the above basic test case slightly, modulating the so that a different element of the sum in (7) is non-zero. Let us take 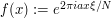 ,
, 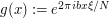 ,
, 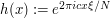 for some fixed frequency
for some fixed frequency 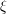 ; then (4) is again equal to
; then (4) is again equal to 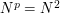 , while (6) is equal to
, while (6) is equal to
![\displaystyle \sum_{n,r \in {\Bbb Z}/N{\Bbb Z}} e^{2\pi i [ a n + b (n+r) + c(n+2r)] \xi / N}.](../images/tex/752256d81eb550ec06d0dc5010f112d0.png)
In order for this to equal for any , we need the linear form 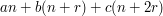 to vanish identically, which forces
to vanish identically, which forces  and
and  . We can normalise
. We can normalise 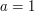 (by using the change of variables
(by using the change of variables 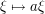 ), thus leading us to the correct expression for (7), namely
), thus leading us to the correct expression for (7), namely
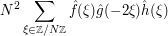 .
.
Once one actually has this formula, of course, it is a routine matter to check that it actually is the right answer.
Remark
One can also calibrate in (7) by observing the identity 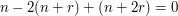 (which reflects the fact that the second derivative of a linear function is necessarily zero), which gives a modulation symmetry
(which reflects the fact that the second derivative of a linear function is necessarily zero), which gives a modulation symmetry 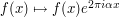 ,
, 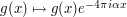 ,
, 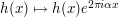 to (6). Inserting this symmetry into (7) reveals that and as before.
to (6). Inserting this symmetry into (7) reveals that and as before.
Remark
By choosing appropriately normalised conventions, one can avoid some calibration duties altogether. For instance, when using Fourier analysis on a finite group such as , if one expects to be analysing functions that are close to constant (or subsets of the group of positive density), then it is natural to endow physical space with normalised counting measure (and thus, by Pontryagin duality, frequency space should be given non-normalised counting measure). [Conversely, if one is analysing functions concentrated on only a bounded number of points, then it may be more convenient to give physical space counting measure and frequency space normalised counting measure.] In practical terms, this means that any physical space sum, such as 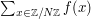 , should instead be replaced with a physical space average
, should instead be replaced with a physical space average 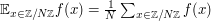 , while keeping sums over frequency space variables unchanged; when one does so, all powers of "miraculously" disappear, and there is no longer any need to calibrate using the constant function as was done above. Of course, this does not eliminate the need to perform other calibrations, such as that of the coefficients above.
, while keeping sums over frequency space variables unchanged; when one does so, all powers of "miraculously" disappear, and there is no longer any need to calibrate using the constant function as was done above. Of course, this does not eliminate the need to perform other calibrations, such as that of the coefficients above.
Comments
Post new comment
(Note: commenting is not possible on this snapshot.)