Here's a simple result in the same spirit: if H is a subgroup of G of index n, then there is a normal subgroup K of G contained in H of index dividing n!. Proof: G acts by left multiplication on the coset space G/H, which has cardinality n. There are only n! possible ways any group element can act here, so the set of elements which act trivially is a subgroup of index dividing n!. But one easily checks that this subgroup is a normal subgroup that is contained in H.
This looks nice, but I for one will not understand it without some help with basic definitions. Here are the ones I don't know: non-central section (or any kind of section for that matter), derived subgroup. I sort of half remember what a characteristic subgroup is but wouldn't mind being reminded.
Incidentally, when this article is in a more finished state, it will also be a useful contribution to the page on how to use group actions.
to be pedantic, the bound would be O(nlog n) because if the symbols are not all distinct, you can "compress" the representation size down, though how much depends on the distribution of symbols, eg use a huffman encoding of the symbols.
I feel like the article is vague around what I consider the main reason for nlog n popping up so often – the exponential structure of any tree, and the depth of the tree being calculated by a logarithm.
That is, considering an algorithm on n elements where some operation occurs n times, things are often structured in a tree than for each operation one potentially reaches the maximal depth of the tree, so one simply multiplies n operations by the depth of the tree.
There's got to be an even clearer way of expressing that, though.
Often n log n pops up for the following reason. If I have a set of n elements, and I want to represent the set as a binary string, the natural thing to do is represent each element as a binary string of length log n. n such strings then require total length n log n to represent.
I've now turned the headings into ordinary text-style links and removed the artificial links in the succeeding paragraphs, for stylistic consistency. And I think it's clearer too, though the headings do look a little small.
Since it doesn't show up directly in the article history, I should mention that this article is basically written by Ben Green. I've moved it over from the page How to use compactness, which is now a navigation page, and added one example (the one on the complex plane).
If V is any non-empty subset of U, does it follow that it must be an initial segment of some set W in the chain. This does not seem necessary. Does any non-empty subset of U have to contain the minimal element?
The following seems like a natural addition to this article: is every finitely additive probability measure on the integers countably additive? The answer could be a proof of the ultrafilter lemma by appealing to Zorn's lemma, which gives that the answer is no.
Similar functions, such as (which can also be though of as "half-way" between polynomial and exponential) arise as the running times of various algorithms for factoring integers.
I believe it should say: is thought of as being "half-way" between *exponential* functions and polynomials, in a similar manner to how is though of as being "half-way" between *constants* and polynomials.
In the first case, I believe it was just a typo. In the second case, "bounded function" could be a bit misleading. For example, I don't think many people would consider as "half-way" between and , even if they would consider it "half-way" between a constant function and .
It would be nice if there were an article on using various graph decompositions. For example, it is very frequently useful to decompose a graph into one or more of the following:
- connected components (or strongly connected components if dealing with directed graphs)
- 2-connected components
- a tree decomposition (a la treewidth)
- a clique decomposition (a la clique width)
- some sort of product of other graphs (Cartesian product is particularly nice because it satisfies unique factorization)
- others?
I am not experienced enough to write such an article, but thought I'd throw the idea out there.
So it's not possible to find out who wrote a new article, without editing it first? In this case I think I have a good guess ;) but it might be harder later in the project, when anyone can make a new article.
Writing "2 times 3" as "2.3" is a bit confusing; perhaps you could use "2
Can the notation be explained? Is![K[x]](../images/tex/a77a9131b3530308247cff0e3c92321a.png) different from
different from 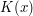 different from
different from 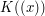 ?
?
Here's a simple result in the same spirit: if H is a subgroup of G of index n, then there is a normal subgroup K of G contained in H of index dividing n!. Proof: G acts by left multiplication on the coset space G/H, which has cardinality n. There are only n! possible ways any group element can act here, so the set of elements which act trivially is a subgroup of index dividing n!. But one easily checks that this subgroup is a normal subgroup that is contained in H.
This looks nice, but I for one will not understand it without some help with basic definitions. Here are the ones I don't know: non-central section (or any kind of section for that matter), derived subgroup. I sort of half remember what a characteristic subgroup is but wouldn't mind being reminded.
Incidentally, when this article is in a more finished state, it will also be a useful contribution to the page on how to use group actions.
to be pedantic, the bound would be O(nlog n) because if the symbols are not all distinct, you can "compress" the representation size down, though how much depends on the distribution of symbols, eg use a huffman encoding of the symbols.
I feel like the article is vague around what I consider the main reason for nlog n popping up so often – the exponential structure of any tree, and the depth of the tree being calculated by a logarithm.
That is, considering an algorithm on n elements where some operation occurs n times, things are often structured in a tree than for each operation one potentially reaches the maximal depth of the tree, so one simply multiplies n operations by the depth of the tree.
There's got to be an even clearer way of expressing that, though.
A picture of selfsame would also help here.
This could be the subject of another, more detailed, article.
It would be great to include an example to illustrate that. Can you suggest a good one?
Often n log n pops up for the following reason. If I have a set of n elements, and I want to represent the set as a binary string, the natural thing to do is represent each element as a binary string of length log n. n such strings then require total length n log n to represent.
I wrote something on this (the "dyadic pigeonhole principle") at
http://www.math.ucla.edu/~tao/preprints/Expository/pigeonhole.dvi
I may try to convert this to the wiki format, but probably not soon.
I've now turned the headings into ordinary text-style links and removed the artificial links in the succeeding paragraphs, for stylistic consistency. And I think it's clearer too, though the headings do look a little small.
Since it doesn't show up directly in the article history, I should mention that this article is basically written by Ben Green. I've moved it over from the page How to use compactness, which is now a navigation page, and added one example (the one on the complex plane).
Perhaps, there can be entries here on estimating probabilities and expectations.
Some estimation methods for probabilities and expectations:
The claim here is that the element is a minimal element of
is a minimal element of 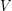 not just with respect to the ordering on
not just with respect to the ordering on 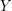 but also with respect to the ordering on
but also with respect to the ordering on 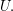
There is no assumption here that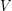 is an initial segment, but
is an initial segment, but 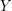 is an initial segment, and if
is an initial segment, and if 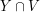 is non-empty then
is non-empty then 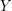 must contain the minimal element.
must contain the minimal element.
"This must be minimal in V as well " instead of "This must be minimal in U as well".
If V is any non-empty subset of U, does it follow that it must be an initial segment of some set W in the chain. This does not seem necessary. Does any non-empty subset of U have to contain the minimal element?
The following seems like a natural addition to this article: is every finitely additive probability measure on the integers countably additive? The answer could be a proof of the ultrafilter lemma by appealing to Zorn's lemma, which gives that the answer is no.
Similar functions, such as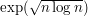 (which can also be though of as "half-way" between polynomial and exponential) arise as the running times of various algorithms for factoring integers.
(which can also be though of as "half-way" between polynomial and exponential) arise as the running times of various algorithms for factoring integers.
In the first half of my last comment I was thinking of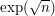 , which can be though of as "half-way" between polynomial
, which can be though of as "half-way" between polynomial 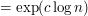 and exponentials like
and exponentials like 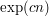 .
.
I believe it should say: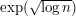 is thought of as being "half-way" between *exponential* functions and polynomials, in a similar manner to how
is thought of as being "half-way" between *exponential* functions and polynomials, in a similar manner to how 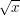 is though of as being "half-way" between *constants* and polynomials.
is though of as being "half-way" between *constants* and polynomials.
In the first case, I believe it was just a typo. In the second case, "bounded function" could be a bit misleading. For example, I don't think many people would consider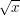 as "half-way" between
as "half-way" between 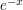 and
and  , even if they would consider it "half-way" between a constant function and
, even if they would consider it "half-way" between a constant function and  .
.
Thanks – I've changed "bounded" to "constant".
It would be nice if there were an article on using various graph decompositions. For example, it is very frequently useful to decompose a graph into one or more of the following:
- connected components (or strongly connected components if dealing with directed graphs)
- 2-connected components
- a tree decomposition (a la treewidth)
- a clique decomposition (a la clique width)
- some sort of product of other graphs (Cartesian product is particularly nice because it satisfies unique factorization)
- others?
I am not experienced enough to write such an article, but thought I'd throw the idea out there.
That's a good point – one should be able to find out who wrote an article. I'll put this on the to-do list.
So it's not possible to find out who wrote a new article, without editing it first? In this case I think I have a good guess ;) but it might be harder later in the project, when anyone can make a new article.
Not too much is lost, hopefully, since the link to each page also occurs in the paragraph immediately following the heading.