It's not clear to me whether this should be a single article with various different ways of using subsequences, or whether each different way deserves its own article. This is a general question about the whole of the Tricki – at what point does one split an article up? Another question: how should the first technique relate to How to use the Bolzano-Weierstrass theorem?
I like "Prove convergence using subsequences" (just one 'sub') for the title. It encapsulates well the general idea. Another: "There is more than one way to prove convergence using subsequences".
I agree mostly with you in this issue - Imperative and how-to titles are desirable. That's why I created stubs for "How to work without an identity element when you clearly need it", etc.
But my main purpose creating this article was not to explain how to use idempotents (for that, I created the other articles). My main purpose was to help those people that has heard about Peirce decomposition but does not see anything special about it.
The main example I have in mind (I'm new to the field, so there's not that much I can think of!)is when you want to prove a categorical statement about a ring without identity (mostly about R-Mod), and typical "universal" or homological techniques with pretty diagrams do not seem to work; then your "other option" is to switch to ring decompositions like Peirce's (or, in a sort of generalization of this, to exploit some Morita context if you have it).
As far as I can tell (that is, very little!), the name "Peirce decomposition" is standard in ring theory (which is my area of expertise, but I've been on it just for six months now!). I can't be sure about changing the title to something more general about idempotents, because there are other, related but different (if I'm not mistaken!), ways of using idempotents. For example, we say that a ring (not necessarily with unity)has enough idempotents if there exists a subset of orthogonal idempotents (,), so that we can decompose as a direct sum of the principal right ideals (equivalently ). Note that must be infinite in order to be interesting. I wanted to write different articles for these two concepts (and one more general, titled "How to work without an identity element when you clearly need it" introducing also sets of local units, firm rings, etc).
I agree that the "more general" statement is not right just now: indeed, we must ask for to have identity and also the set should be finite (I wrote it late and I somewhat messed the idea up with the enough idempotents thing!).
Actually, I didn't lift anything of PlanetMath! I just made a quick summary on my own. I checked now with PlanetMath, there is an obvious resemblance because it is a definition but I don't see that much of a coincidence!
I've discussed titles quite a bit in this forum post. If you buy my view about imperative titles, then you could consider "Exploit idempotents in a ring." But it depends whether the point of the article is more "You might not have thought of it, but idempotents are actually very useful," or "You have seen or heard that idempotents can be useful, but here is how to produce such arguments for yourself." If the former, then I would be very much in favour of the imperative title. Or one could go for something more specific, such as "Decompose your ring using idempotents." The ideal, in my view is a title that serves as a super-quick summary of the message of the entire article. It's not always possible to achieve that, but often it is.
Yes, I was thinking about the tensor product for abelian groups as a special case of a product construction (in Ring theory it is quite usual to think of everything as modules). Feel free to change it as you say, I added it just as a suggestion (I put it on the list because there really isn't any more on the stub at the moment!)
The above example has a more sophisticated method than the one I tried to describe in the quick description section. In the generalization of the method of example 1, there would be a function and the goal would be to improve our understanding of its smoothness. To that end, we use itself to define another function
such that , and is as smooth as . Now the implicit function theorem says is as smooth as and hence . The argument is continued as many steps as possible. Does anyone know of another application of this argument, or an argument similar to this?
Tensor products are not really defined for groups, but rather for modules
over rings. Abelian groups are-modules, and so tensor products are defined for abelian groups, but this is a construction of a very different flavour
to all the other constructions listed on this page.
Perhaps it would be better to have a comment somewhere on the page to this effect
(i.e. that one can define the tensor product of two abelian groups), and then just
link to the How to use tensor products page for more details.
If there are no objections, I will do this some time soon.
I propose changing the title of this article to ``How to exploit idempotents in a ring''.
I have used this idea many times in my research, but never knew it was called the Peirce decomposition until reading this article. Indeed, it is a standard example in the theory of schemes, and in the representation theory of p-adic groups, which motivate two of the above examples, but I have never seen it referred to by this name in any books on those subjects. (I say this just as a defense in advance of my ignorance of this name; I don't think I will be unique in having an interest in this article, while not knowing the name ``Peirce decomposition".)
If there are no objections within a day or so, I will make this change. I will then add a line to the quick description along the lines of ``this decomposition is sometimes refereed to as the Peirce decomposition of with respect to ''.
Also, the ``More generally'' remark about a complete system of orthogonal idempotents should be elaborated on. (Because if does not have an identity, then is not actually defined as an element of , and so the Peirce decomposition is itself more general than decomposing with respect to orthogonal idempotents. So while the decomposition by a complete system of orthogonal idempotents is very closely related to the Peirce decomposition, it does not always contains the latter as a special case. Indeed, the notion of a complete system of orthogonal idempotents probalby only makes sense if has an identity, at least as far as I can tell.)
Finally, I noticed that the earlier version of this article was to some extent lifted from PlanetMath. Maybe we should be careful doing this in general, just for copyright reasons.
That's true, if you ask for the trichotomy law axiom, then both definitions are equivalent. I don't know exactly how nonstandard is this, but since Wikipedia and Planetmath both mention it (Mathworld doesn't!), it should be safe. Maybe in the transfinite context it is more used? (I just checked my copy of Kamke's "Theory of Sets". He uses your convention!).
Excuse me for my comment, I thought the notation was somewhat confusing (but it was more like I was the one confused!)
I always thought that a total order could be strict, and that the condition was that , or . Is that a very nonstandard convention?
The relation on the ordinals is more convenient to use than , since one wants many statements to be true for every , for some given . I suppose one could add the word "strict" in brackets before the first occurrence of "total order", but that feels a bit strange, given that you can convert orders of the type into orders of the type and back again. Indeed, because of this I describe them both as total orders and think of them as different ways of describing the same basic underlying object.
A total order is supposed to be total, in the sense that for every pair , we have either or . Choosing the symbol instead of for the total order can be deceptive because it usually means "lesser but not equal". It's clear that this order isn't total, because we don't have . So, either it is a mistake or it is a conscious choice of the symbol. I haven't changed the notation myself precisely because there could be a good explanation to do it like this. If I don't receive an answer in several days I will change it.
I am thinking that the use of polar coordinates could be another entry in methods for simplifying integrals (or in general methods for estimating integrals). Of course the example in this article is maybe an elementary one but one could think of more involved examples in singular integrals (e.g. method of rotations) where essentially this principle is the basic trick. I understand that 'polar coordinates' is probably quite restrictive. We should probably have an entry along the lines 'try to change your coordinate system'. I think it is a standard trick in estimating oscillatory integrals as well. Stein does this in order to prove the multi-dimensional version of the van der Corput lemma with a bump function, and I think also Michael Christ has done that in a couple of papers in order to prove sub-level set estimates (but I can't say i have all the details in my head right now). That is, adopts the coordinate system to the direction along which the phase function has a derivative that stays bounded away from zero and uses a one dimensional estimate along this direction. I guess there are plenty of other cases that I don't know of. On the other hand maybe this should be part of an 'exploit symmetries and invariance' article if one thinks for example the way Stein proves the dimension free bounds for the Euclidean ball-maximal function. I am getting a bit confused concerning which is the natural or 'right' place for each article.
When this article is written, it should have examples of several different styles of inductive proof: the usual kind where you deduce from , the slightly more sophisticated kind where you deduce it from the fact that is true for every , induction over more sophisticated well-ordered sets, use of the well-ordering principle, etc.
Amusingly, I planned an article ages ago that was very similar in spirit to this one. I've just looked for a dead link but can't find one. Anyhow, it's great that you've started this one, which I hope may eventually fit in nicely as a special case of a more general principle, which is what my intended article was going to be about. The general principle is that whenever you need to choose something and it feels difficult to do so because you need to guess too much about how the rest of the proof will go, you have the option of not choosing it and instead taking some abstract object instead, running the rest of the proof, and seeing what properties you need your unspecified object to have. At that point, you have a new problem: is there an object with those properties? Often this problem is much clearer and easier than the problem you had before when you didn't know how the proof would go.
Numerical examples in analysis are an obvious source of examples. I use the general idea a lot, but when it came to writing the article I suddenly found I couldn't think of any. Perhaps I'll write a stub with a general discussion – roughly equal to the above paragraph – but no examples! And then it could be a parent for this article.
(Actually I am only now just beginning to realise the sheer scope of this project - it may end up making the Princeton Companion to Mathematics seem like a short story!) My strategy at this point is to lay down a large number of stubs and let them grow, develop, merge, etc. in unexpected ways, on the theory that the more articles already exist, the more likely it is that each potential contributor can find a niche.
I also want to write down a number of proofs of the Cauchy-Schwarz inequality here, as some of them emphasise some cute tricks (e.g. optimising in a parameter to be chosen later). I suppose initially we can put "How to use X" and "Proof of X" on the same page, though as discussed in the "different kind of article" thread we may eventually want to split them into two (interlinked) pages.
In this article, "decoupling" sounds as an interesting general strategy. We could add a parent article about this more general metatechnique (I don't have the knowledge to elaborate it). Why is it important? In which cases ought we try to get a decoupling? Etc
Another "decoupling" technique that comes to mind now is that of "separating variables" in ODEs and PDEs.
I think we have similar views on these things. My guess is what you refer to as the sample space in your statement ``...but for most other things once can avoid mentioning the sample space'' is the in, for example, the following statement:
``Let be a probability space and let ,, ..., ,... be a sequence of iid Bernoulli random variables with ''
Unfortunately, it is common in probability to state the structures that underly the problem in this abstract and obscure way. What is the remedy? I think the remedy is to explicitly state what these things are for the problem at hand. For example, I would rewrite the above statement as follows:
``
Let and .
Let .
Define for , and let be the unique extension of to . Let be the coordinate projections.''
One can write it in different ways but the point is: explicitly state what your maps are, what your sigma algebras are.
I think that the concepts of sigma algebras, measurability, maps, etc. are very well thought abstractions that are useful at every level, including, finite sets. If for nothing else, for notational and pedagogical reasons. For example: the notation is good, it allows us to talk about the result of an experiment. How to make this notation meaningful? Here is an example: If the experiment is the throw of a die, then , and finally the random variable is , is simply the canonical map. Is this abstract nonsense? I don't think so. Now I can soundly write .
Philosophically, I find this setup meaningful as well. is the identity map. Why? Because we model the experiment as random, i.e., we have settled to accept that we don't know the causes that determine the outcomes of the roll of our die. If we did then the causes would have been the domain of and would actually be a function mapping the causes to the effects. We throw away the causes and the relation between the causes and the effects and define as a map that maps each effect to itself. And as far as our knowledge of the experiment goes, we settle to simply live with the statistical properties of the outcomes, which we represent as a probability distribution.
From the pedagogical point of view: I ask my students nontrivial measurability questions in finite setups so that they get a good sense of what measurability means in cases where they can explicitly write down the objects they are working on. I think this is good preparation for times when one has to think about measuribility in much more abstract circumstances.
I think there should exist some examples involving trigonometric (or inverse trigonometric) functions, where we forget about the actual evaluations of the functions but we use their main properties, like periodicity, a sine is a cosine with a phase change, bounds between and ,,, etc.
More generally, I think we almost always do this abstraction: for us, mathematical objects are mostly what their main properties say they are; for example, we just associate every function with their properties, not with their sets of values (e.g., exponentials are the functions that verify the rules of exponentiation, are always positive, eigenfunctions for the derivative operator, etc). And when we define a family of "well-known" functions (for example, "elemental" functions and operations to represent an undefined integral), we are just restricting ourselves to functions whose properties we know well. I think this main idea could be the subject of another, even more abstract article about "Forget the actual object and stand by its properties" (not just for functions).
(Actually, I also want to write an article some day titled "Just check the definition", because sometimes it shows more fruitful to just stick to the definition of the object in question rather than trying characterizations and well-known properties of it. If you read this and feel like writing that article, feel free to do so!).
I've thought about this, and in the end I think it isn't really an example, because its algorithmic nature isn't playing a genuine role. The "real" proof that underlies the argument you give is this: take all maximal open subintervals of your set, and check that no two of them can intersect.
One sees that any open set is the union of disjoint intervals using a greedy algorithm. For an element in let , be the collection of all open intervals lying in and containing . Let and The intervals in are open, connected and they are not disjoint of each other because they all contain . These imply that is also a member of and by its definition it is the maximal element of .
We now enumerate the rationals in and iterate over them as follows. Suppose ,,..., are the intervals chosen upon iterating over the first rationals. For the rational we check if intersects with ,,...,. If there is a nonempty intersection with a then by the maximality of and in this case we complete the step and proceed to the next rational. If is disjoint from ,,..., then we let .
Let be the largest number the index reaches in the above iteration (it may be ). Because the rationals are dense in it follows that .
Actually, my view is more nuanced than my last comment would suggest. Having just taught a probability course, I think that one should define a random variable as a (measurable – though I prefer to start with the discrete case) function on a probability space, one should try as hard as possible not to use this in proofs. It's very convenient to use it when proving linearity of expectation, but for most other things one can avoid mentioning the sample space. Perhaps I'll write a Tricki article called something like "How not to think about sample spaces."
Thanks for the comment. I do hope that you and others will feel free to edit any of what I wrote here, I understand that it can be written better.
On the issue of what is probability theory I would like to share a sentence from Doob from his book Stochastic Processes:
``Probability is simply a branch of measure theory, with its own special emphasis and field of application, and no attempt has been made to suger-coat this fact. (page 1)''
Your point about the first sentence being incomplete and dry, I do agree. I couldn't come up with something better at a first writing. Here is again a better statement by Doob, which, similar to your sentence, emphasizes the relations rather than the objects:
``The theory of probability is concerned with the measure properties of various spaces, and with the mutual relations of measurable functions defined on those spaces. (Stochastic processes, page 2).''
Dear Jose,
Sorry for the unfair PlanetMath comment; indeed, it must just be that there are not all that many ways to describe the basics of this concept.
Best wishes,
Matthew
It's not clear to me whether this should be a single article with various different ways of using subsequences, or whether each different way deserves its own article. This is a general question about the whole of the Tricki – at what point does one split an article up? Another question: how should the first technique relate to How to use the Bolzano-Weierstrass theorem?
I like "Prove convergence using subsequences" (just one 'sub') for the title. It encapsulates well the general idea. Another: "There is more than one way to prove convergence using subsequences".
I agree mostly with you in this issue - Imperative and how-to titles are desirable. That's why I created stubs for "How to work without an identity element when you clearly need it", etc.
But my main purpose creating this article was not to explain how to use idempotents (for that, I created the other articles). My main purpose was to help those people that has heard about Peirce decomposition but does not see anything special about it.
The main example I have in mind (I'm new to the field, so there's not that much I can think of!)is when you want to prove a categorical statement about a ring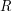 without identity (mostly about R-Mod), and typical "universal" or homological techniques with pretty diagrams do not seem to work; then your "other option" is to switch to ring decompositions like Peirce's (or, in a sort of generalization of this, to exploit some Morita context if you have it).
without identity (mostly about R-Mod), and typical "universal" or homological techniques with pretty diagrams do not seem to work; then your "other option" is to switch to ring decompositions like Peirce's (or, in a sort of generalization of this, to exploit some Morita context if you have it).
Thanks a lot for the editions!
As far as I can tell (that is, very little!), the name "Peirce decomposition" is standard in ring theory (which is my area of expertise, but I've been on it just for six months now!). I can't be sure about changing the title to something more general about idempotents, because there are other, related but different (if I'm not mistaken!), ways of using idempotents. For example, we say that a ring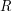 (not necessarily with unity)has enough idempotents if there exists a subset
(not necessarily with unity)has enough idempotents if there exists a subset 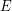 of orthogonal idempotents (
of orthogonal idempotents (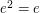 ,
, 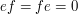 ), so that we can decompose
), so that we can decompose 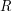 as a direct sum of the principal right ideals
as a direct sum of the principal right ideals 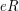 (equivalently
(equivalently 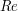 ). Note that
). Note that 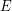 must be infinite in order to be interesting. I wanted to write different articles for these two concepts (and one more general, titled "How to work without an identity element when you clearly need it" introducing also sets of local units, firm rings, etc).
must be infinite in order to be interesting. I wanted to write different articles for these two concepts (and one more general, titled "How to work without an identity element when you clearly need it" introducing also sets of local units, firm rings, etc).
I agree that the "more general" statement is not right just now: indeed, we must ask for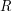 to have identity and also the set should be finite (I wrote it late and I somewhat messed the idea up with the enough idempotents thing!).
to have identity and also the set should be finite (I wrote it late and I somewhat messed the idea up with the enough idempotents thing!).
Actually, I didn't lift anything of PlanetMath! I just made a quick summary on my own. I checked now with PlanetMath, there is an obvious resemblance because it is a definition but I don't see that much of a coincidence!
I've discussed titles quite a bit in this forum post. If you buy my view about imperative titles, then you could consider "Exploit idempotents in a ring." But it depends whether the point of the article is more "You might not have thought of it, but idempotents are actually very useful," or "You have seen or heard that idempotents can be useful, but here is how to produce such arguments for yourself." If the former, then I would be very much in favour of the imperative title. Or one could go for something more specific, such as "Decompose your ring using idempotents." The ideal, in my view is a title that serves as a super-quick summary of the message of the entire article. It's not always possible to achieve that, but often it is.
Yes, I was thinking about the tensor product for abelian groups as a special case of a product construction (in Ring theory it is quite usual to think of everything as modules). Feel free to change it as you say, I added it just as a suggestion (I put it on the list because there really isn't any more on the stub at the moment!)
The above example has a more sophisticated method than the one I tried to describe in the quick description section. In the generalization of the method of example 1, there would be a function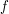 and the goal would be to improve our understanding of its smoothness. To that end, we use
and the goal would be to improve our understanding of its smoothness. To that end, we use 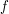 itself to define another function
itself to define another function
such that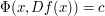 ,
, 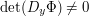 and
and 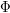 is as smooth as
is as smooth as 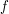 . Now the implicit function theorem says
. Now the implicit function theorem says 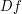 is as smooth as
is as smooth as 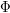 and hence
and hence 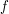 . The argument is continued as many steps as possible. Does anyone know of another application of this argument, or an argument similar to this?
. The argument is continued as many steps as possible. Does anyone know of another application of this argument, or an argument similar to this?
Tensor products are not really defined for groups, but rather for modules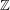 -modules, and so tensor products are defined for abelian groups, but this is a construction of a very different flavour
-modules, and so tensor products are defined for abelian groups, but this is a construction of a very different flavour
over rings. Abelian groups are
to all the other constructions listed on this page.
Perhaps it would be better to have a comment somewhere on the page to this effect
(i.e. that one can define the tensor product of two abelian groups), and then just
link to the How to use tensor products page for more details.
If there are no objections, I will do this some time soon.
I propose changing the title of this article to ``How to exploit idempotents in a ring''.
I have used this idea many times in my research, but never knew it was called the Peirce decomposition until reading this article. Indeed, it is a standard example in the theory of schemes, and in the representation theory of p-adic groups, which motivate two of the above examples, but I have never seen it referred to by this name in any books on those subjects. (I say this just as a defense in advance of my ignorance of this name; I don't think I will be unique in having an interest in this article, while not knowing the name ``Peirce decomposition".)
If there are no objections within a day or so, I will make this change. I will then add a line to the quick description along the lines of ``this decomposition is sometimes refereed to as the Peirce decomposition of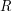 with respect to
with respect to  ''.
''.
Also, the ``More generally'' remark about a complete system of orthogonal idempotents should be elaborated on. (Because if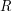 does not have an identity, then
does not have an identity, then 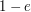 is not actually defined as an element of
is not actually defined as an element of 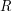 , and so the Peirce decomposition is itself more general than decomposing with respect to orthogonal idempotents. So while the decomposition by a complete system of orthogonal idempotents is very closely related to the Peirce decomposition, it does not always contains the latter as a special case. Indeed, the notion of a complete system of orthogonal idempotents probalby only makes sense if
, and so the Peirce decomposition is itself more general than decomposing with respect to orthogonal idempotents. So while the decomposition by a complete system of orthogonal idempotents is very closely related to the Peirce decomposition, it does not always contains the latter as a special case. Indeed, the notion of a complete system of orthogonal idempotents probalby only makes sense if 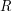 has an identity, at least as far as I can tell.)
has an identity, at least as far as I can tell.)
Finally, I noticed that the earlier version of this article was to some extent lifted from PlanetMath. Maybe we should be careful doing this in general, just for copyright reasons.
That's true, if you ask for the trichotomy law axiom, then both definitions are equivalent. I don't know exactly how nonstandard is this, but since Wikipedia and Planetmath both mention it (Mathworld doesn't!), it should be safe. Maybe in the transfinite context it is more used? (I just checked my copy of Kamke's "Theory of Sets". He uses your convention!).
Excuse me for my comment, I thought the notation was somewhat confusing (but it was more like I was the one confused!)
I always thought that a total order could be strict, and that the condition was that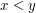 ,
, 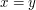 or
or 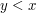 . Is that a very nonstandard convention?
. Is that a very nonstandard convention?
The relation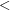 on the ordinals is more convenient to use than
on the ordinals is more convenient to use than 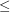 , since one wants many statements to be true for every
, since one wants many statements to be true for every 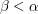 , for some given
, for some given  . I suppose one could add the word "strict" in brackets before the first occurrence of "total order", but that feels a bit strange, given that you can convert orders of the
. I suppose one could add the word "strict" in brackets before the first occurrence of "total order", but that feels a bit strange, given that you can convert orders of the 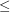 type into orders of the
type into orders of the 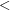 type and back again. Indeed, because of this I describe them both as total orders and think of them as different ways of describing the same basic underlying object.
type and back again. Indeed, because of this I describe them both as total orders and think of them as different ways of describing the same basic underlying object.
A total order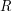 is supposed to be total, in the sense that for every pair
is supposed to be total, in the sense that for every pair  , we have either
, we have either 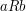 or
or 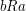 . Choosing the symbol
. Choosing the symbol 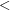 instead of
instead of 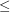 for the total order can be deceptive because it usually means "lesser but not equal". It's clear that this order isn't total, because we don't have
for the total order can be deceptive because it usually means "lesser but not equal". It's clear that this order isn't total, because we don't have 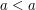 . So, either it is a mistake or it is a conscious choice of the symbol. I haven't changed the notation myself precisely because there could be a good explanation to do it like this. If I don't receive an answer in several days I will change it.
. So, either it is a mistake or it is a conscious choice of the symbol. I haven't changed the notation myself precisely because there could be a good explanation to do it like this. If I don't receive an answer in several days I will change it.
I am thinking that the use of polar coordinates could be another entry in methods for simplifying integrals (or in general methods for estimating integrals). Of course the example in this article is maybe an elementary one but one could think of more involved examples in singular integrals (e.g. method of rotations) where essentially this principle is the basic trick. I understand that 'polar coordinates' is probably quite restrictive. We should probably have an entry along the lines 'try to change your coordinate system'. I think it is a standard trick in estimating oscillatory integrals as well. Stein does this in order to prove the multi-dimensional version of the van der Corput lemma with a bump function, and I think also Michael Christ has done that in a couple of papers in order to prove sub-level set estimates (but I can't say i have all the details in my head right now). That is, adopts the coordinate system to the direction along which the phase function has a derivative that stays bounded away from zero and uses a one dimensional estimate along this direction. I guess there are plenty of other cases that I don't know of. On the other hand maybe this should be part of an 'exploit symmetries and invariance' article if one thinks for example the way Stein proves the dimension free bounds for the Euclidean ball-maximal function. I am getting a bit confused concerning which is the natural or 'right' place for each article.
yannis
When this article is written, it should have examples of several different styles of inductive proof: the usual kind where you deduce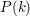 from
from 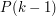 , the slightly more sophisticated kind where you deduce it from the fact that
, the slightly more sophisticated kind where you deduce it from the fact that 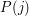 is true for every
is true for every 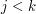 , induction over more sophisticated well-ordered sets, use of the well-ordering principle, etc.
, induction over more sophisticated well-ordered sets, use of the well-ordering principle, etc.
Amusingly, I planned an article ages ago that was very similar in spirit to this one. I've just looked for a dead link but can't find one. Anyhow, it's great that you've started this one, which I hope may eventually fit in nicely as a special case of a more general principle, which is what my intended article was going to be about. The general principle is that whenever you need to choose something and it feels difficult to do so because you need to guess too much about how the rest of the proof will go, you have the option of not choosing it and instead taking some abstract object instead, running the rest of the proof, and seeing what properties you need your unspecified object to have. At that point, you have a new problem: is there an object with those properties? Often this problem is much clearer and easier than the problem you had before when you didn't know how the proof would go.
Numerical examples in analysis are an obvious source of examples. I use the general idea a lot, but when it came to writing the article I suddenly found I couldn't think of any. Perhaps I'll write a stub with a general discussion – roughly equal to the above paragraph – but no examples! And then it could be a parent for this article.
(Actually I am only now just beginning to realise the sheer scope of this project - it may end up making the Princeton Companion to Mathematics seem like a short story!) My strategy at this point is to lay down a large number of stubs and let them grow, develop, merge, etc. in unexpected ways, on the theory that the more articles already exist, the more likely it is that each potential contributor can find a niche.
I also want to write down a number of proofs of the Cauchy-Schwarz inequality here, as some of them emphasise some cute tricks (e.g. optimising in a parameter to be chosen later). I suppose initially we can put "How to use X" and "Proof of X" on the same page, though as discussed in the "different kind of article" thread we may eventually want to split them into two (interlinked) pages.
In this article, "decoupling" sounds as an interesting general strategy. We could add a parent article about this more general metatechnique (I don't have the knowledge to elaborate it). Why is it important? In which cases ought we try to get a decoupling? Etc
Another "decoupling" technique that comes to mind now is that of "separating variables" in ODEs and PDEs.
I think we have similar views on these things. My guess is what you refer to as the sample space in your statement ``...but for most other things once can avoid mentioning the sample space'' is the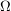 in, for example, the following statement:
in, for example, the following statement:
``Let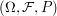 be a probability space and let
be a probability space and let 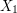 ,
, 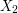 , ...,
, ...,  ,... be a sequence of iid Bernoulli random variables with
,... be a sequence of iid Bernoulli random variables with 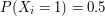 ''
''
Unfortunately, it is common in probability to state the structures that underly the problem in this abstract and obscure way. What is the remedy? I think the remedy is to explicitly state what these things are for the problem at hand. For example, I would rewrite the above statement as follows: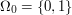 and
and 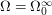 .
.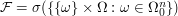 .
.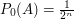 for
for 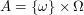 ,
, 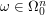 and let
and let 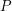 be the unique extension of
be the unique extension of 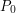 to
to 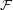 . Let
. Let 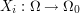 be the coordinate projections.''
be the coordinate projections.''
``
Let
Let
Define
One can write it in different ways but the point is: explicitly state what your maps are, what your sigma algebras are.
I think that the concepts of sigma algebras, measurability, maps, etc. are very well thought abstractions that are useful at every level, including, finite sets. If for nothing else, for notational and pedagogical reasons. For example: the notation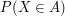 is good, it allows us to talk about the result
is good, it allows us to talk about the result 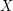 of an experiment. How to make this notation meaningful? Here is an example: If the experiment is the throw of a die, then
of an experiment. How to make this notation meaningful? Here is an example: If the experiment is the throw of a die, then 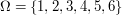 ,
,  and finally the random variable is
and finally the random variable is 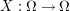 ,
, 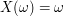 is simply the canonical map. Is this abstract nonsense? I don't think so. Now I can soundly write
is simply the canonical map. Is this abstract nonsense? I don't think so. Now I can soundly write 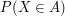 .
.
Philosophically, I find this setup meaningful as well.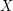 is the identity map. Why? Because we model the experiment as random, i.e., we have settled to accept that we don't know the causes that determine the outcomes of the roll of our die. If we did then the causes would have been the domain of
is the identity map. Why? Because we model the experiment as random, i.e., we have settled to accept that we don't know the causes that determine the outcomes of the roll of our die. If we did then the causes would have been the domain of 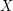 and
and 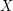 would actually be a function mapping the causes to the effects. We throw away the causes and the relation between the causes and the effects and define
would actually be a function mapping the causes to the effects. We throw away the causes and the relation between the causes and the effects and define 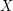 as a map that maps each effect to itself. And as far as our knowledge of the experiment goes, we settle to simply live with the statistical properties of the outcomes, which we represent as a probability distribution.
as a map that maps each effect to itself. And as far as our knowledge of the experiment goes, we settle to simply live with the statistical properties of the outcomes, which we represent as a probability distribution.
From the pedagogical point of view: I ask my students nontrivial measurability questions in finite setups so that they get a good sense of what measurability means in cases where they can explicitly write down the objects they are working on. I think this is good preparation for times when one has to think about measuribility in much more abstract circumstances.
I think there should exist some examples involving trigonometric (or inverse trigonometric) functions, where we forget about the actual evaluations of the functions but we use their main properties, like periodicity, a sine is a cosine with a phase change, bounds between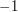 and
and 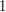 ,
, 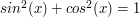 ,
, 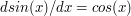 , etc.
, etc.
More generally, I think we almost always do this abstraction: for us, mathematical objects are mostly what their main properties say they are; for example, we just associate every function with their properties, not with their sets of values (e.g., exponentials are the functions that verify the rules of exponentiation, are always positive, eigenfunctions for the derivative operator, etc). And when we define a family of "well-known" functions (for example, "elemental" functions and operations to represent an undefined integral), we are just restricting ourselves to functions whose properties we know well. I think this main idea could be the subject of another, even more abstract article about "Forget the actual object and stand by its properties" (not just for functions).
(Actually, I also want to write an article some day titled "Just check the definition", because sometimes it shows more fruitful to just stick to the definition of the object in question rather than trying characterizations and well-known properties of it. If you read this and feel like writing that article, feel free to do so!).
I've thought about this, and in the end I think it isn't really an example, because its algorithmic nature isn't playing a genuine role. The "real" proof that underlies the argument you give is this: take all maximal open subintervals of your set, and check that no two of them can intersect.
Would the following example be too trivial?
One sees that any open set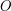 is the union of disjoint intervals using a greedy algorithm. For an element
is the union of disjoint intervals using a greedy algorithm. For an element  in
in 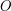 let
let 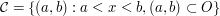 , be the collection of all open intervals lying in
, be the collection of all open intervals lying in 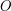 and containing
and containing  . Let
. Let 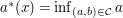 and
and 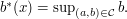 The intervals in
The intervals in 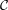 are open, connected and they are not disjoint of each other because they all contain
are open, connected and they are not disjoint of each other because they all contain  . These imply that
. These imply that 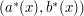 is also a member of
is also a member of 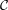 and by its definition it is the maximal element of
and by its definition it is the maximal element of 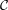 .
.
We now enumerate the rationals in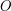 and iterate over them as follows. Suppose
and iterate over them as follows. Suppose 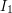 ,
, 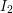 ,...,
,...,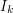 are the intervals chosen upon iterating over the first
are the intervals chosen upon iterating over the first 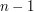 rationals. For the
rationals. For the 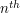 rational
rational 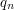 we check if
we check if 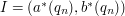 intersects with
intersects with 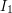 ,
, 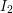 ,...,
,...,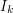 . If there is a nonempty intersection with a
. If there is a nonempty intersection with a 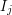 then
then 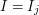 by the maximality of
by the maximality of 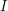 and in this case we complete the step and proceed to the next rational. If
and in this case we complete the step and proceed to the next rational. If 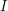 is disjoint from
is disjoint from 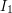 ,
, 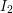 ,...,
,...,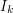 then we let
then we let 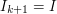 .
.
Let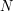 be the largest number the index
be the largest number the index 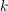 reaches in the above iteration (it may be
reaches in the above iteration (it may be 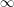 ). Because the rationals are dense in
). Because the rationals are dense in 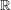 it follows that
it follows that 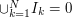 .
.
Actually, my view is more nuanced than my last comment would suggest. Having just taught a probability course, I think that one should define a random variable as a (measurable – though I prefer to start with the discrete case) function on a probability space, one should try as hard as possible not to use this in proofs. It's very convenient to use it when proving linearity of expectation, but for most other things one can avoid mentioning the sample space. Perhaps I'll write a Tricki article called something like "How not to think about sample spaces."
I think the identification of random variables and measurable functions is standard. For example, Varadhan's Probability Theory book, page 7:
``An important notion is that of a random variable or a measurable function.''
then the next definition:
``Definition 1.5. A random variable or a measurable function is a map ...''
Another example is the book Probabilities and Potential by [[w:Paul-Andr
Thanks for the comment. I do hope that you and others will feel free to edit any of what I wrote here, I understand that it can be written better.
On the issue of what is probability theory I would like to share a sentence from Doob from his book Stochastic Processes:
``Probability is simply a branch of measure theory, with its own special emphasis and field of application, and no attempt has been made to suger-coat this fact. (page 1)''
Your point about the first sentence being incomplete and dry, I do agree. I couldn't come up with something better at a first writing. Here is again a better statement by Doob, which, similar to your sentence, emphasizes the relations rather than the objects:
``The theory of probability is concerned with the measure properties of various spaces, and with the mutual relations of measurable functions defined on those spaces. (Stochastic processes, page 2).''